| GenBank® is the NIH genetic
sequence database, an annotated collection of all publicly available DNA
sequences. GenBank is part of the International Nucleotide Sequence Database
Collaboration, which comprises the DNA DataBank of Japan (DDBJ), the European
Molecular Biology Laboratory (EMBL), and GenBank at NCBI. These three organizations
exchange data on a daily basis. Many journals
require submission of sequence information to a database prior to publication
so that an accession number may appear in the paper. The sequence data
submitted by an investigator to any of the three databases appears in all
of them and is available to all users.
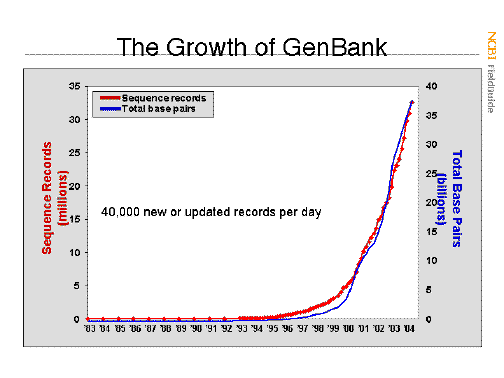
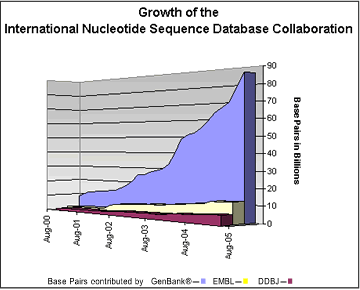
The amount of information in GenBank
has grown exponentially, and in August 2005
it exceeded 100 gigabases (1 x 1012).
Of these, approximately 90 billion were in GenBank, 10 billion in EMBL
and 5 billion in DDBJ. As of February 2006, there are approximately 59,750,386,305
bases in 54,584,635 sequence records in the traditional GenBank divisions
and 63,183,065,091 bases in 12,465,546 sequence records in the WGS division.
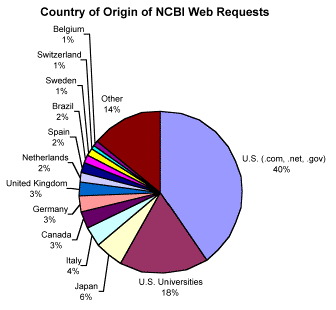
Access to the databases comes from
almost every country in the world, although U.S.
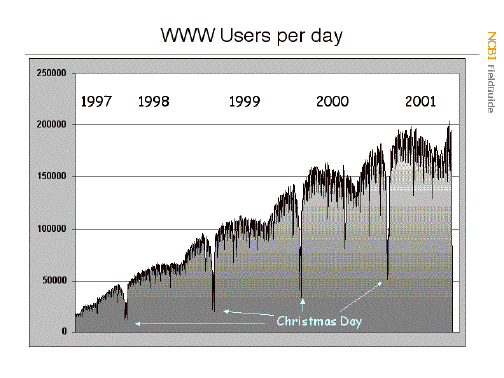
companies and U.S. universities are by far the largest users. The number
of data requests has increased steadily since 1997 with predictable
dips during summer vacation times and especially on Christmas Day (although
there were still over 50,000 hits by exceptionally geeky computational
biologists in 2000!)
GenBank
provides the base sequence, the translated amino acid sequence and references
for each record stored in GenBank. In addition information is given
about the position of any coding sequences identified within the record,
and the putative function of the protein.
GenBank was recently (ca. early 2006)
split into 3 divisions, and is now referred to as the Umbrella
Nucleotides Data Base. The three divisions
of the Umbrella Nucleotides Data Base are: 1.) the Core
Nucleotides data base (DNA, mRNA sequences); 2.) the EST
data base(expressed sequence tags); 3.) the GSS
data base (genomic sequences). |
{kind=link}
{kind=link}
{kind=link}
{kind=link}