|
TUTORIAL #2: Dissection
of a GenBank Record
Fot this tutorial we will be looking at a gene for auxin found in the
plant Arabidopsis Thaliana.
This gene was located by searching
Entrez for records related to auxins in plants. The gene is located
in a clone from chromosome 2 in Arabidopsis thaliana. As shown,
this clone contains 114,144 bp. A number of genes are located within this
clone. One of these genes codes for a putative auxin-binding protein. It
is 801 bp long, and is spans the bases 63391 - 62591.
| xxx |
LOCUS
U78721 114144 bp DNA linear PLN 27-FEB-2002
DEFINITION
Arabidopsis thaliana chromosome 2 clone T1B8 map TEn5.
ACCESSION
U78721
VERSION
U78721.3 GI:20198308
KEYWORDS
HTG.
SOURCE
thale cress.
ORGANISM
Arabidopsis thaliana |
The Features
Table for the putative auxin-binding gene provides
information on the hnRNA, and the locations of the Introns and Exons. It
also shows the actual CDS of the mature mRNA, and the protein translation
as derived from the CDS.



|
|
Click on
the ""REVIEW" button to review Introns and Exons.
Open the image to the left ..... it
will help you understand the key points below!
-
The third line in the Features Table (with numbers
in red) refers to the heterogenous RNA (hnRNA).
-
The sequence of the hnRNA corresponds
to the complement of the sequence given in this record.
-
The gene extends from base 63391 to 62591, so the gene is 801 bp long
inclusive. Prove
to yourself that it is not 800 bp long!
-
However the gene has 3 exons
which total to 603 bp long inclusive.
-
exon-1 extends from base 63391 to 63248, and is 144 bp long.
-
exon-2 extends from base 63135 to 62943, and is 193 bp long.
-
exon-3 extends from base 62856 to 62591, and is 266 bp long.
-
This means that there are 2 introns
which must be 198 bp long in total.
-
intron-1 (between exon-1 and exon-2) extends from 63247 to 63136 and must
be 112 bp long.
-
intron-2 (between exon-2 and exon-3) extends from 62942 to 62857 and must
be 86 bp long.
-
Why does it appear that intron-2 is before intron-1?
-
The fifth line of the Features Table shows the actual
coding sequences (CDS) in the mature
processed mRNA excluding the 5' UTRs and 3' UTRs.
-
the coding sequence of exon-1 begins at base 63338 - not 63391!
This means that there must be a 53 bp 5' UTR.
-
the coding sequence of exon-3 ends at 62820 - not 62591. This means
there must be 229 bp of 3' UTR!
-
The eleventh line of the Feature Table shows the amino
acid translation, given from the N-terminal to
C-terminal
ends.
-
The protein begins with methionine.
-
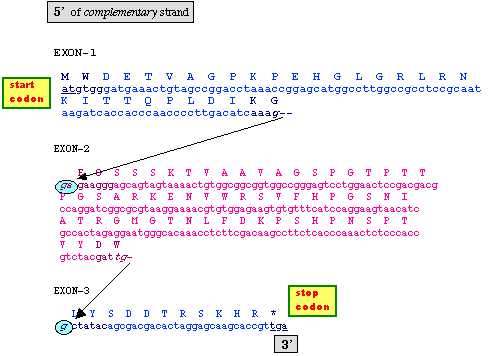
The amino acids coded in exon-1 are colored blue.
-
The amino acids coded in exon-2 are colored pink.
-
The amino acids coded in exon-3 are colored blue.
|
|
|
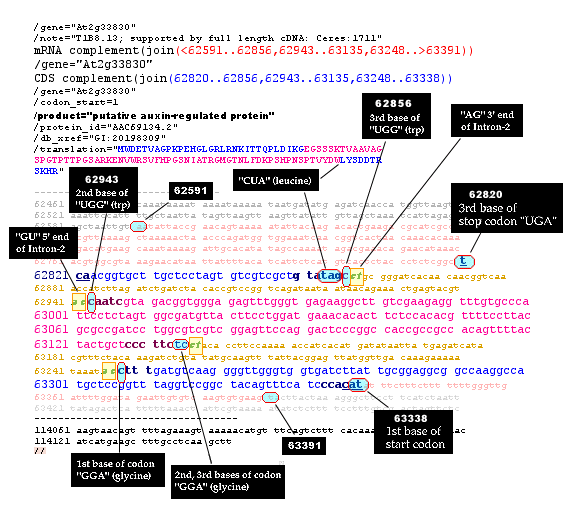
The ORIGIN
Table shows the original DNA sequence which was
submitted to GenBank. The section of the tutorial below explains how the
annotation provided in the Features Table for the putative auxin-binding
gene correspond with the original base sequence.


 |
|
Open
the image to the left ..... it will help you understand the key points
below!
This is the actual genomic sequence of the gene for this auxin-regulated
protein. The full sequence of the hnRNA - including 5' and 3' UTR's, and
the two introns - is shown bounded in rose in smaller fonts.
Genbank always gives sequences in the 5'--->3' direction. However
the coding sequence for this gene is the complement of this
sequence, and must therefore be read in the 3' --> 5' direction (from bottom
right to upper left)!
It has been color coded to illustrate the structure of the locus as
given in the annotation above: blue=exon-1 and exon-3; pink=exon-2; gold (small font)= intervening sequences; rose (small font)=
5' and 3; UTRs; "gu" and "ag" splice signals
at the 5' and 3' ends of the introns = green letters inside yellow boxes.
The start codon
and stop codon are underlined.
NOTE the following!
-
As shown in the annotation, the gene begins at base 63391 with the
5' UTR.
-
As shown in the annotation, the coding sequence begins at base 63338
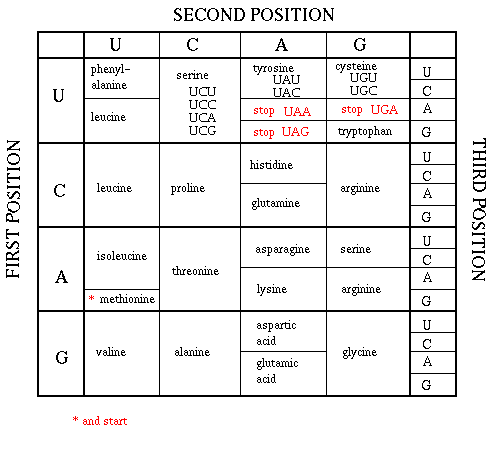
with the "tac" codon. The complements is "atg" - the methionine start
codon!
-
As shown in the annotation, intron-1 begins with base 63247. The
RNA complement of "ca" is "gu" the conserved doublet at the
5' end of an intron.
-
As shown in the annotation, intron-1 ends with base 63136. The RNA
complement of "tc" is "ag" the conserved doublet at the 5'
end of an intron.
-
As shown in the annotation, the coding sequence ends at base 62820
with the triplet "act". The RNA complement of "act" is "uga" - one
of the three stop codons!
Not only are the coding sequences split, but even individual codons
may be split between two exons!
-
The splice site between exon-1 and exon-2 occurs in the middle
of the triplet codon for glycine! The last full codon of exon-1 is
"ttt" (complement is "aaa" the codon for lysine).
The next codon is "cct" (RNA complement is "ggu", the
codon for glycine.) The first base of "cct"
is at the 3' end of exon-1, but the second and third bases are at the 5'
end of exon-2!
-
The splice site between exon-2 and exon-3 occurs in the middle
of the triplet codon for tryptophan! The last full codon of exon-2
is "cta" (RNA
complement is "gau" the codon for aspartic acid).
The next codon is "acc" (complement is "ugg", the codon for tryptophan.)
The first and second bases of "acc" are at the 3' end of exon-2, but the
third base is at the 5' end of exon-3.
The image to the left shows the nucleotide sequence, in register
with, the translation as given above in the Feature Table. It begins with
the start codon at the 5' end of exon-1, indicates the two splice sites
and ends with the stop codon at the 3' end of exon-3.
|
|

{kind=link}
{kind=link}