The GenBank Flat File Format
![]()
LOCUS Section |
REFERENCES Section |
![]()
|
| TUTORIAL (20-30
minutes)
The GenBank flat files contain a large amount of information. However, it is presented in a highly telegraphic style. Although the information in itself is generally straightforward, some background on the format aids in decoding the information. To begin this tutorial, go to the NCBI home page. From the Search pull-down menu, select "Nucleotide", and click on "Go". The "Entrez Nucleotide" page should appear, which looks like this. Type U49845 into the search box, and click on the "Go" button. When the results of the search are displayed, there should be a link to "U49845", the TCP1-beta gene in Saccharomyces cervisiae (Bakers Yeast). Click on this link. The nucleotide record whose Accession Number is U49845 - which looks like this- should appear.
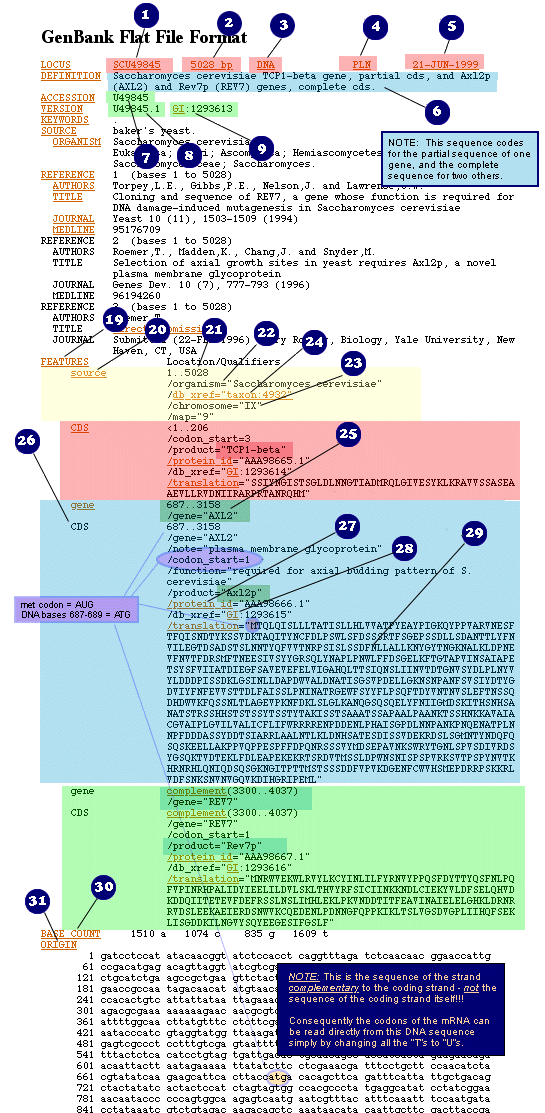
Look at this sample file and its organization during the rest of this tutorial.
|
| LOCUS Section |
|
Locus Name (1) The locus name was originally designed to help group entries with similar sequences:
|
| Molecule Type (3)
The type of molecule that was sequenced. Each GenBank record must contain contiguous sequence data from a single molecule type. The various molecule types can include:
|
| GenBank Division (4)
The GenBank database is divided into 17 divisions: 1. PRI - primate
sequences
Some of the divisions contain sequences from specific groups of organisms, while others (EST, GSS, HTG, etc.) contain data generated by specific sequencing technologies from many different organisms. The organismal divisions are historical and do not reflect the current NCBI Taxonomy. Instead, they merely serve as a convenient way to divide GenBank into smaller pieces for those who want to FTP the database. Because of this, and because sequences from a particular organism can exist in technology-based divisions such as EST, HTG, etc., the NCBI Taxonomy Browser should be used for retrieving all sequences from a particular organism.
|
| Modification Date (5)
The date in the LOCUS field is the date of last modification. In some cases, it might correspond to the release date, but there is no way to tell just by looking at the record. If you need to know the first date of public availability for a specific sequence record, send a message to info@ncbi.nlm.nih.gov. We will check the history of the record for you, and let you know the date of first public release. If the sequence was originally submitted to our collaborators at DDBJ or EMBL, rather than to GenBank, we will ask them to send the release date information to you.
|
| DEFINITION (6)
Brief description of sequence; includes information such as:
In this example, the DNA sequence encodes 3 genes:
|
| ACCESSION
(7)
The unique identifier for a sequence record. An accession number applies to the complete record and is usually a combination of a letter(s) and numbers, such as
Note: compare accession number with Sequence Identifiers such as Version and GI for nucleotide sequences, and ProteinID and GI for amino acid sequences.
|
| VERSION
(8)
A nucleotide sequence identification number that represents a single, specific sequence in the GenBank database. This identification number uses the accession.version format implemented by GenBank/EMBL/DDBJ in February 1999.If there is any change to the sequence data (even a single base) the version number will be increased by 0.1, e.g., U12345.1 --> U12345.2, but the accession portion will remain the same. The accession.version system of sequence identifiers runs parallel to the GI number system. That is, when any change is made to a sequence, it receives a new GI number AND an increase to its version number.
|
| GI (9)
"GenInfo Identifier" sequence identification number, in this case, for the nucleotide sequence. If a sequence changes in any way, a new GI number will be assigned. A separate GI number is also assigned to each protein translation within a nucleotide sequence record, and a new GI is assigned if the protein translation changes in any way (see below). GI numbers start with "g" if assigned by GenBank, "d" if assigned by DDBJ or "e" if assigned by EMBL. GI sequence identifiers run parallel to the new accession / version system of sequence identifiers. For more information, see the description of Version, above, and section 3.4.7 of the current GenBank release notes.
|
| KEYWORDS (10)
Word or phrase describing the sequence. If no keywords are included in the entry, the field contains only a period! The Keyword field is present in sequence records primarily for historical reasons, and is not based on a controlled vocabulary. Keywords are generally present in older records. They are not included in newer records unless: (1) they are not redundant with any feature, qualifier, or other information present in the record |
| SOURCE
(11)
Free-format information including an abbreviated form of the organism name - this may be a common name or scientific name. It is sometimes followed by a molecule type.
|
| Organism (12)
The formal scientific name for the source organism (genus and species,
where appropriate) and its lineage, based on the phylogenetic classification
scheme used in the NCBI
Taxonomy Database. If the complete lineage of an organism is very long,
an abbreviated lineage will be shown in the GenBank record and the complete
lineage will be available in the Taxonomy Database.
|
| REFERENCES Section |
| FEATURES TABLE Section (19) |
Definitions of the elements of the Features Table:
|
| BASE COUNT and ORIGIN Section |
|
|
|
{kind=link}
{kind=link}