Ensemble learning

The problem of overfitting
We’ve seen how we can construct a decision tree to make predictions or perform classification. However, like any variety of machine learning, there’s often a tension between model accuracy and the risk of overfitting.
Overfitting occurs when our model (whatever the type) has effectively memorized the data it has been trained on. When overfitting has occurred, when we measure the accuracy of model predictions on data it’s seen during training, the model performs well, but when we test the model on new data—data that it has never seen before—it performs poorly. In other words, the model does not generalize well to new data. Decision trees are prone to this, just like any other kind of model.
Consider what happens when we try to fit a line to some data. If we fit with a straight line, there can be considerable error of estimate for any given point.
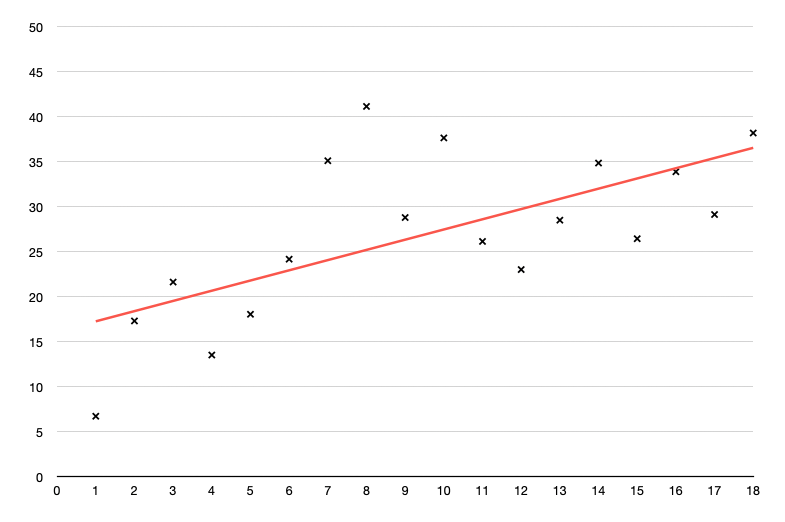
We can reduce our error by fitting with a polynomial curve. Here we see a fit with a cubic curve (polynomial of degree 3).
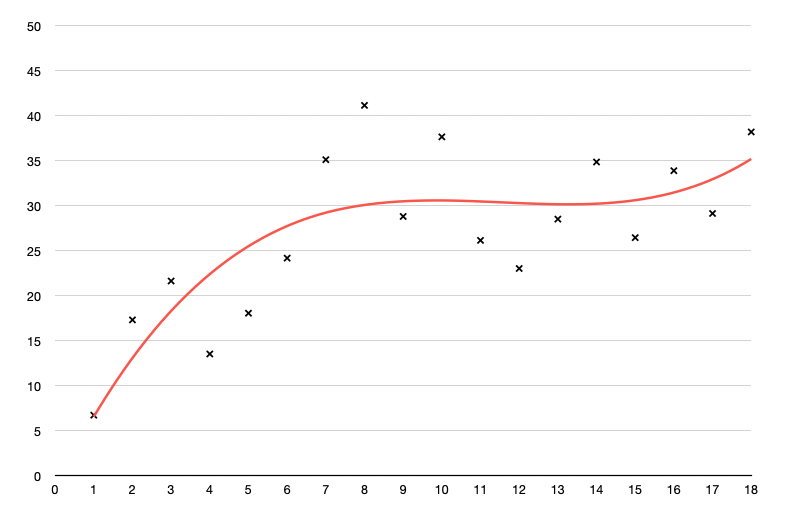
Here’s the fit for a sixth-degree polynomial.
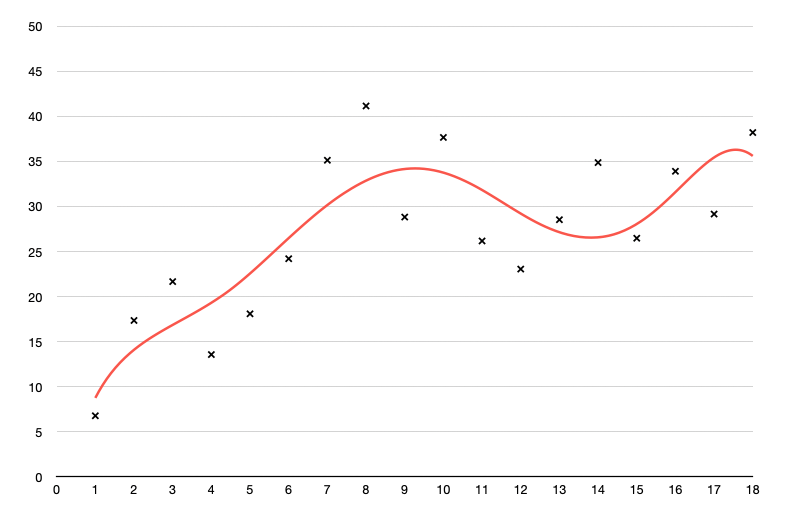
We could continue this to higher-degree polynomial curves and fit to arbitrary accuracy. However the more closely we fit a particular data set, the greater the risk that we’ll overfit, that our model is too complex, and that when presented with new data (inputs to our polynomial function), we make bad predictions. This is the danger of overfitting and decision trees are not immune.
Let’s say we were building a model to classify certain varieties of flowering plant, and we had ten attributes (e.g., color, petal dimensions, numbers of petals, and so on). Let’s say we limited the depth of our decision tree to five, and we got 90% accuracy of classifications on training data, and we got 90% accuracy on test data (data not used to fit the model). Now let’s say we tried to improve model accuracy and so we set the depth limit to seven. We run the model on training data and we get 96% accuracy—a big boost. But next, we run the model on test data—again, these are data the model has not seen during training. However, on the test data our accuracy has fallen from 90% to 83%! What has happened? Overfitting. We’ve made our model too complex, it’s memorized the training data, and now it doesn’t generalize well.
We’d like to improve model accuracy on test data, but if we add complexity we end up overfitting? What is to be done in cases like this?
Ensemble learning
One approach is called ensemble learning. The idea is simple, we make use of the wisdom of the crowd. Rather than trying to construct the one “perfect” decision tree to solve a classification problem, we generate a large number of trees and then look for consensus (or majority). This is particularly useful in a complex problem. It’s quite possible that a problem might be more than a single decision tree can handle. Neither of these scenarios is uncommon.
Ensemble learning to the rescue.
- we make multiple decision trees, and
- we let the decision trees “vote” on a given test instance.
Consider this simplified scenario:
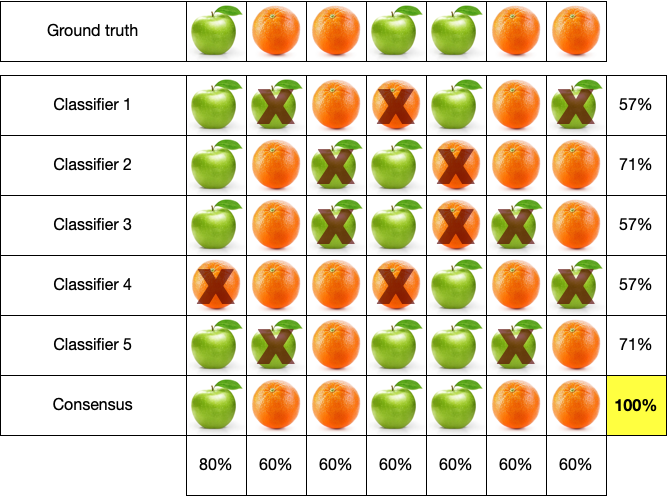
Here we’re trying to classify fruits as either apples or oranges. The “ground truth” is shown at the top for reference. We have five different classifiers, and we show their predicted classifications. Incorrect classifications are marked with “X”.
Notice what’s going on here. None of the predictors alone is very accurate. Indeed, they range from 57% to 71% accuracy. That’s pretty lousy—57% isn’t much better than a coin toss, and 71% is nothing to write home about. Looking at the columns (each representing a test instance) we see that accuracy for any given test instance ranges from 60% to 80%, with an average of 63%. Again, that’s not so hot. But observe what happens when we take the consensus: 100% accuracy. Now, of course, this is an idealized example but it illustrates an important point: the consensus of a large number of weak predictors can be a strong predictor!
In the case of decision trees which produce categorical predictions (yes/no; benign/malignant; maple, pine, or hawthorn; etc.) we have “hard” voting. Other kinds of model give probabilistic answers which permit “soft” voting.
Let’s see more about the power of ensemble learning. Say we have five independent classifiers, each with accuracy of 70%. That is,
- n = 5 (the number of classifiers)
- p = 0.7 (the accuracy of each classifier)
With hard voting, three is a majority, so we consider all the cases where k the number of correct predictions is at least three. That is,
- k \geq 3 (the number of correct predictions: 3/5, 4/5, 5/5 all majority)
Now the binomial theorem allows us to compute the results for independent trials.
\begin{align*} P(x=k) &= \binom{n}{k}p^{k}(1-p)^{n-k} \\[1em] &= \frac{n!}{k!(n-k)!}p^k(1-p)^{n-k} \end{align*}
So for the three cases we need to consider with k \geq 3, we have
\begin{align*} P(x=3) &= \binom{5}{3} 0.7^3 0.3^2 = 0.309 \\[1em] P(x=4) &= \binom{5}{4} 0.7^4 0.3^1 = 0.360 \\[1em] P(x=5) &= \binom{5}{5} 0.7^5 0.3^0 = 0.168 \\[1em] \end{align*}
Summing all of these, we get
P(x=3) + P(x=4) + P(x=5) = 0.309 + 0.360 + 0.168 = 0.837 \approx 83.7\% \text{ accuracy!}
Not bad. With just five independent models each with only 70.0\% accuracy, we’d expect 83.7\% accuracy from the ensemble. If we were to increase the number of classifiers to 100, we’d achieve over 99.9% accuracy!
However to achieve this, the classifiers must be independent. Why? Because if we have correlated errors among classifiers we don’t have independent predictions.
So ensemble learning is a powerful technique which can substantially boost accuracy, while helping to avoid overfitting. However, the complete independence of members of the ensemble is impossible to achieve in practice, but we can do pretty well if we’re careful.
We have an approach to building an ensemble of decision trees called “random forest” and that’s our next topic.
(The author tips his hat to TA Layla Musallam for assistance in typing up hen-scratched notes.)
Copyright © 2023–2026 Clayton Cafiero
No generative AI was used in producing drafts of this material. This was written the old-fashioned way. AI was used to rewrite existing pseudocode in LaTeX to produce standalone *.tex files for rendering, and for revisions toward satisfying WCAG 2.1 AA-level accessibility standards as required by UVM policy. AI may also have been used to proofread selected human-written prose. Claude 2.1 with model Sonnet 4.6. Revisions, if any, were performed by the author. AI was not used in generating any code whatsoever. All code samples and starter code are by the author only.