Decision trees: Mitchell’s tennis (continued)

Mitchell’s tennis example revisited
Let’s return to Mitchell’s tennis example. Recall that we have these observations.
| day | outlook | temp | humidity | wind | play |
|---|---|---|---|---|---|
| 1 | sunny | hot | high | weak | no |
| 2 | sunny | hot | high | strong | no |
| 3 | overcast | hot | high | weak | yes |
| 4 | rain | mild | high | weak | yes |
| 5 | rain | cool | normal | weak | yes |
| 6 | rain | cool | normal | strong | no |
| 7 | overcast | cool | normal | strong | yes |
| 8 | sunny | mild | high | weak | no |
| 9 | sunny | cool | normal | weak | yes |
| 10 | rain | mild | normal | weak | yes |
| 11 | sunny | mild | normal | strong | yes |
| 12 | overcast | mild | high | strong | yes |
| 13 | overcast | hot | normal | weak | yes |
| 14 | rain | mild | high | strong | no |
Our objective is to produce a decision tree which correctly predicts whether Tom’s friend will play tennis on any given Saturday.
We have observed 14 Saturdays, noting the weather conditions, outlook, temperature, humidity, wind, and whether Tom’s friend has played on a given day.
How would we construct a decision tree to predict whether Tom’s friend plays tennis or not?
It’s not so straightforward, there’s no single attribute that can be used.
Tom’s friend plays on some sunny days (9, 11), but does not play on other sunny days (1, 2, 8).
Tom’s friend plays on some windy days (7, 11, 12) but not on others (2, 6, 14).
Similarly with other weather features (humidity and temperature).
So how do we go about this? Remember our ideal is to produce the most pure subsets we can, but that ID3 is a greedy algorithm, with no guarantee of optimality. ID3 tests partitions of our data by all possible attributes and chooses the attribute that gives us the greatest information gain.
\text{Gain}(S, A) \equiv H(S) - \sum\limits_{v\in \text{Values}(A)} \frac{\lvert S_v \rvert}{\lvert S \rvert} H(S_v)
In our tennis example consider our attributes: - outlook, - humidity, - wind, and - temperature.
If we were to use outlook to split our data we’d have:
| sunny | overcast | rainy |
|---|---|---|
| 2 pos/3 neg | 4 pos/0 neg | 3 pos/2 neg |
and recall overall we have nine positive samples (days Tom’s friend plays tennis) and five negative samples (days she does not play tennis).
What’s H(S)?
\begin{align*} H(S) &= -\frac{9}{14} \log_2 \frac{9}{14} - \frac{5}{14} \log_2 \frac{5}{14} \\[1em] &= -0.64 \log_2(0.64) - 0.36 \log_2(0.36) \\[1em] &= -0.64 \times (-0.64) - 0.36 \times -1.49 \\[1em] &= 0.41 + 0.53 = 0.94. \end{align*}
What’s the entropy if we split on outlook?
H(S_{\text{sunny}})=-\frac{2}{5}\log_2\frac{2}{5}-\frac{3}{5}\log_2\frac{3}{5}=0.97
H(S_{\text{overcast}})=-\frac{4}{4}\log_2\frac{4}{4}-\frac{0}{4}\log_2\frac{0}{4}=0.0
H(S_{\text{rainy}})=-\frac{3}{5}\log_2\frac{3}{5}-\frac{2}{5}\log_2\frac{2}{5}=0.97
Now take the weighted average:
\frac{5}{14} \times 0.97 + \frac{4}{14} \times 0.0 + \frac{5}{14} \times 0.97 = 0.69.
So this gives us the information gain
\text{Gain}(S, \text{outlook}) = 0.94 - 0.69 = 0.246.
If we do the same calculation for splits on attributes humidity, temperature, and wind we get
- \text{Gain}(S, \text{humidity}) = 0.151,
- \text{Gain}(S, \text{wind}) = 0.048,
- \text{Gain}(S, \text{temperature}) = 0.029.
So our greedy algorithm chooses outlook as the first attribute on which to split
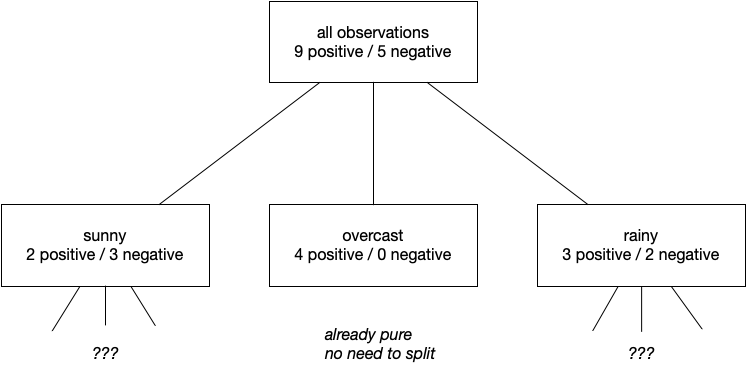
Then we proceed recursively until we have nothing but pure subsets or until some specified maximum depth has been reached.
Here’s the pseudocode for the ID3 algorithm.

Keep in mind that a left-arrow in pseudocode is assignment. Also recall that a backward slash operator (\setminus) is the set difference operator (when operands are sets) so A \setminus B is all the elements of A that are not also in B.
(The author tips his hat to TA Layla Musallam for assistance in typing up hen-scratched notes.)
Copyright © 2023–2026 Clayton Cafiero
No generative AI was used in producing drafts of this material. This was written the old-fashioned way. AI was used to rewrite existing pseudocode in LaTeX to produce standalone *.tex files for rendering, and for revisions toward satisfying WCAG 2.1 AA-level accessibility standards as required by UVM policy. AI may also have been used to proofread selected human-written prose. Claude 2.1 with model Sonnet 4.6. Revisions, if any, were performed by the author. AI was not used in generating any code whatsoever. All code samples and starter code are by the author only.