Decision trees: Mitchell’s tennis example

While our simple animal classification was sufficient to get us started, it’s a rather trivial example. There are many real-world problems that are more complicated (as I’m sure you can imagine).
Rather than dive right in to real-world examples, let’s take a look at another small problem instance, but one that presents us with new challenges.
A canonical example: Mitchell’s friend plays tennis
A canonical example comes to us from Tom Mitchell: playing tennis.
| day | outlook | temp | humidity | wind | play |
|---|---|---|---|---|---|
| 1 | sunny | hot | high | weak | no |
| 2 | sunny | hot | high | strong | no |
| 3 | overcast | hot | high | weak | yes |
| 4 | rain | mild | high | weak | yes |
| 5 | rain | cool | normal | weak | yes |
| 6 | rain | cool | normal | strong | no |
| 7 | overcast | cool | normal | strong | yes |
| 8 | sunny | mild | high | weak | no |
| 9 | sunny | cool | normal | weak | yes |
| 10 | rain | mild | normal | weak | yes |
| 11 | sunny | mild | normal | strong | yes |
| 12 | overcast | mild | high | strong | yes |
| 13 | overcast | hot | normal | weak | yes |
| 14 | rain | mild | high | strong | no |
This table shows 14 observations indicating meteorological conditions and whether or not Tom’s hypothetical friend plays tennis or not on any observed day.
Now let’s say we wanted to construct a decision tree that would accurately predict whether Tom’s friend plays tennis on any given Saturday. That is, we wish to predict one of two classes: days when she plays (“yes”) and days when she does not (“no”). Tom’s friend plays on sunny days but not all sunny days. She plays on all overcast days, but plays on some rainy days. She plays on days with weak or strong winds, and does not play on other days with weak or strong winds.
Keep in mind that our objective is to partition the data into subsets in such a way that it helps classify observations. Once we have a working classification we can make predictions based on observations of meteorological conditions.
Clearly, constructing a decision tree is not at all straightforward. Where do we even begin? We have four attributes—outlook, temperature, humidity, and wind—but how do we order our questions? For example, what’s a good choice for the first question to ask?
We need some more tools to bring to bear on this problem.
ID3 algorithm
There are several approaches to constructing decision trees. One approach is given by the ID3 algorithm (Quinlan, 1986). ID3 (iterative dichotomiser 3) is a top-down greedy search through the space of all possible decision trees. It does not guarantee a best tree. Indeed, finding an optimal tree is \NP-complete! However, ID3 and related algorithms do a very good job of constructing trees, at relatively low computational cost.
The idea behind ID3 (and related algorithms) is that at each branching opportunity the algorithm greedily chooses the attribute that gives the greatest information gain.
Going back to our animal classification for a moment, let’s consider what happens as we move from root to leaf nodes.
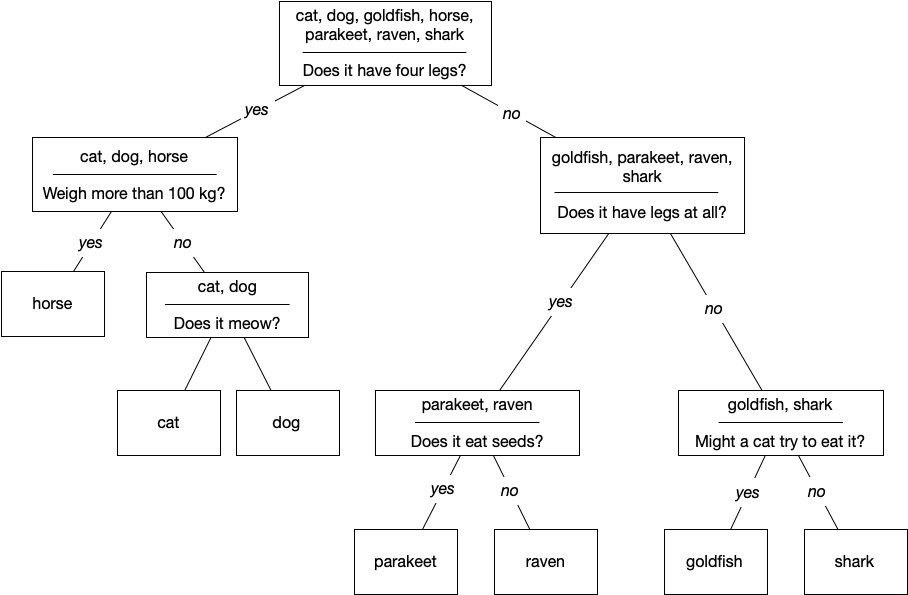
At the root, we have very little information. If we were to close our eyes and choose an element from the root set, we wouldn’t know much about what we’d select. By the time we get to leaf nodes, if we were to sample from the subset of any given leaf, we’d know exactly what we’d get—there’s only one possibility. Clearly, we’ve gained some information. The root set is thoroughly mixed—each of the seven animals is represented in equal proportion. The leaf nodes, in some sense, are “pure.” Their subsets contain only samples of a given class.
So in constructing a decision tree, our goal is to partition data into “pure” subsets. Starting with the entire set, we ask “Which attribute can we use to partition the data into subsets of the highest purity?”
As we move from the root set to leaf nodes, we gain information as the subsets corresponding to the nodes becomes more and more pure. It should be unsurprising that there’s a connection between information gain and increasing purity of subsets. But what do information gain and purity actually mean? To understand this, we’ll need a little digression into information theory.
(The author tips his hat to TA Layla Musallam for assistance in typing up hen-scratched notes.)
Copyright © 2023–2026 Clayton Cafiero
No generative AI was used in producing drafts of this material. This was written the old-fashioned way. AI was used to rewrite existing pseudocode in LaTeX to produce standalone *.tex files for rendering, and for revisions toward satisfying WCAG 2.1 AA-level accessibility standards as required by UVM policy. AI may also have been used to proofread selected human-written prose. Claude 2.1 with model Sonnet 4.6. Revisions, if any, were performed by the author. AI was not used in generating any code whatsoever. All code samples and starter code are by the author only.