Minimax

Minimax
As we’ve said, adversarial games require a new approach. Moreover, the only rational strategy for a given player is to assume optimal play on the part of their opponent. We’ve also introduced the idea of one player being the maximizing player and the other being the minimizing player. It doesn’t matter which is which, but by convention we’ll treat the player to move first as the maximizing player. We’ll refer to these two players as “MAX” and “MIN”.
In the face of an an adversary, the maximizing player, MAX, seeks to maximize the score associated with the current game state and the minimizing player, MIN, seeks to minimize the same score. In choosing the best move, MAX seeks to maximize the minimum gain they’d recieve taking MIN’s moves into consideration. MIN would seek to minimize the maximum gain taking MAX’s moves into consideration. The maximin value, v_i is the best value player i is sure to get without knowing an apponent’s actual next move.
v_i = \underset{a_i}{\text{max}} \; \underset{a_{-i}}{\text{min}} \; v_i(a_i, a_{-i})
where
i is the index of the player of interest, -i denotes all other players (in our scenario there’s only one other player)
a_i is the action taken by player i
a_{-i} is the action taken by all other players (again, in a two-player game there’s only one other), and
v_i is the value function for player i.
Let’s take a look at a simple example with tic-tac-toe.
An example with tic-tac-toe
Consider this position in a game of tic-tac-toe.
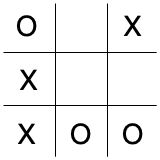
If you know how to play tic-tac-toe (and I’m pretty sure you do) and if you were playing “X” and it were your turn, you’d know exactly what to do. There’s a move that wins immediately. But our goal here is not to rely on our intuition and powers of pattern recognition, but rather to see how we could approach the problem algorithmically so we could build a tic-tac-toe playing program. Toward that end, let’s consider the game tree below this current board state.
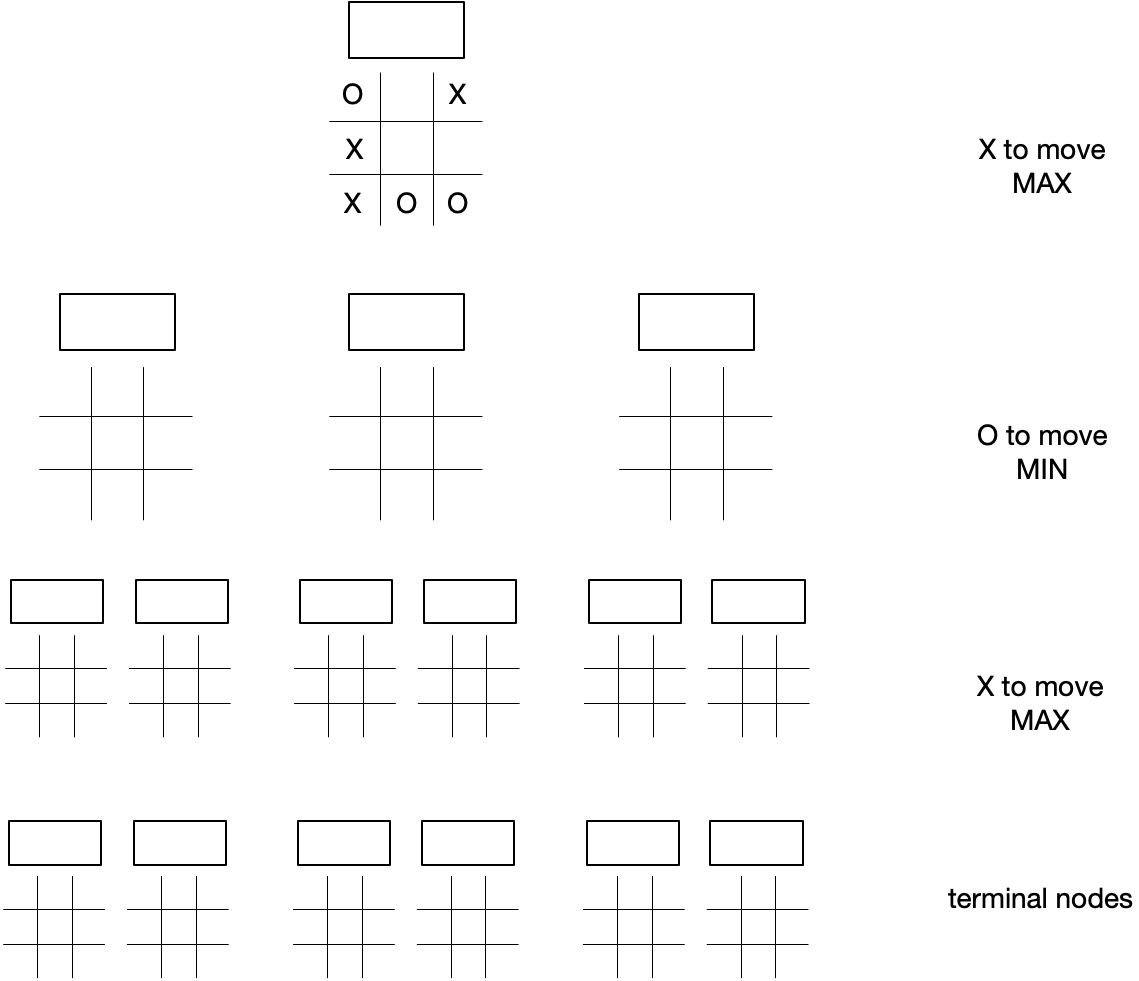
Usually we don’t have the luxury of building a complete game tree, but it’s not burdensome or infeasible in the case of tic-tac-toe because the number of statess is small and the branching factor reduces by one with every move.
Now let’s fill in the game tree with all possible moves (and while we go about it, we’ll eliminate subtrees where we reach a terminal state).
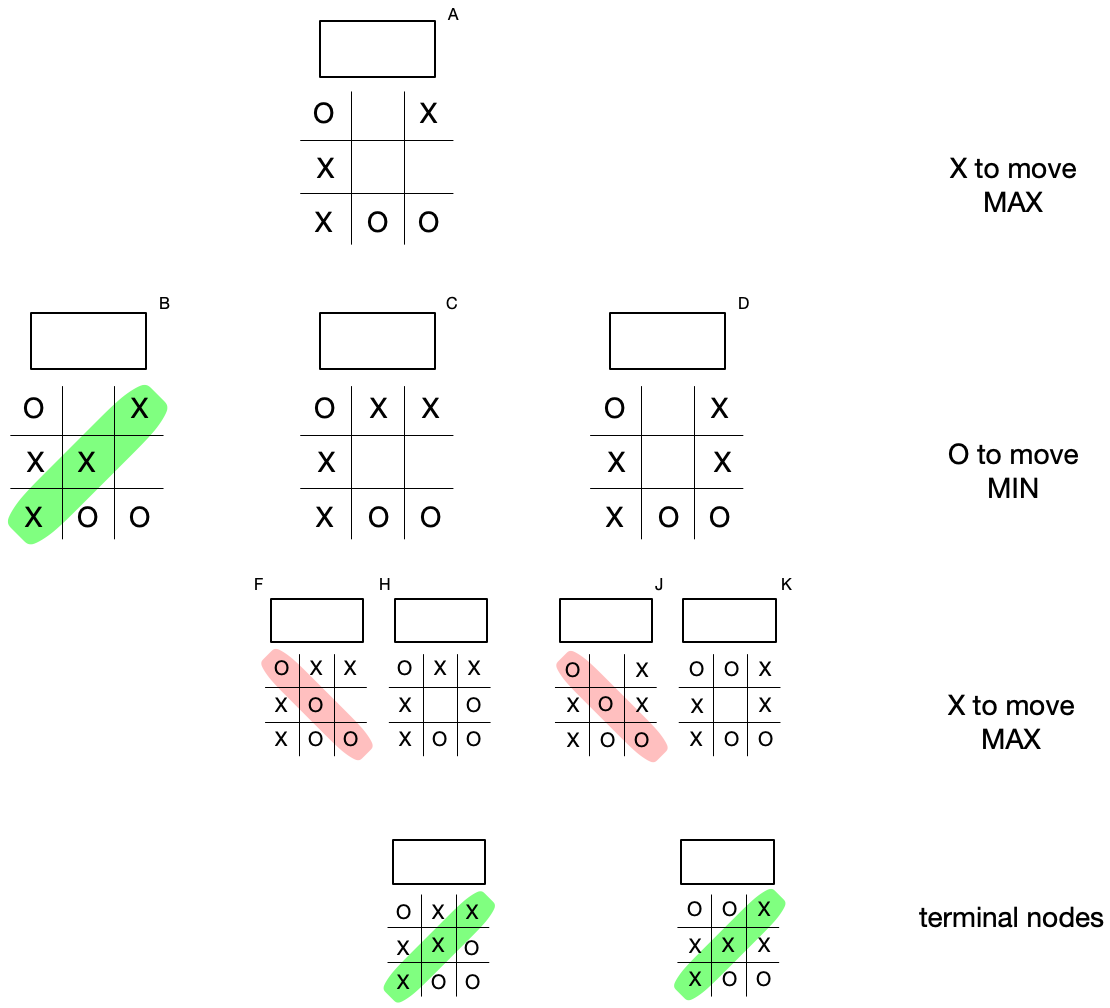
This represents all the possible moves, recursively, given the current board state and the rules of the game. We see that there are some winning states for “X” and some for “O”. Remember that “X” (the maximizing player) and “O” (the minimizing player) take turns, so one tier in our tree represents all of “X”’s possible moves from a given state and another tier represents all of “O”’s possible moves.
Now let’s assign scores to each node in the tree by the following scheme.
- If a node is terminal, that is, it represents a win or tie and the game is over, we assign a score of +10 in the event of a win for “X”, a score of -10 in the event of a win for “O”, and a score of “0” in the event of a tie (there are no such nodes in this tree, but there might be in others).
- Working from leaf nodes up to the root:
- If it is “X”’s move (MAX), “X” chooses the move that maximizes the resulting score. If there are two or more moves yielding the same maximum, “X” may choose any.
- If it is “O”’s move (MIN), “O” chooses the move that minimizes the resulting score. If there are two or more moves yielding the same minimum, “O” may choose any.
- Once the score for the root node is established, this determines the corresponding player’s best move.
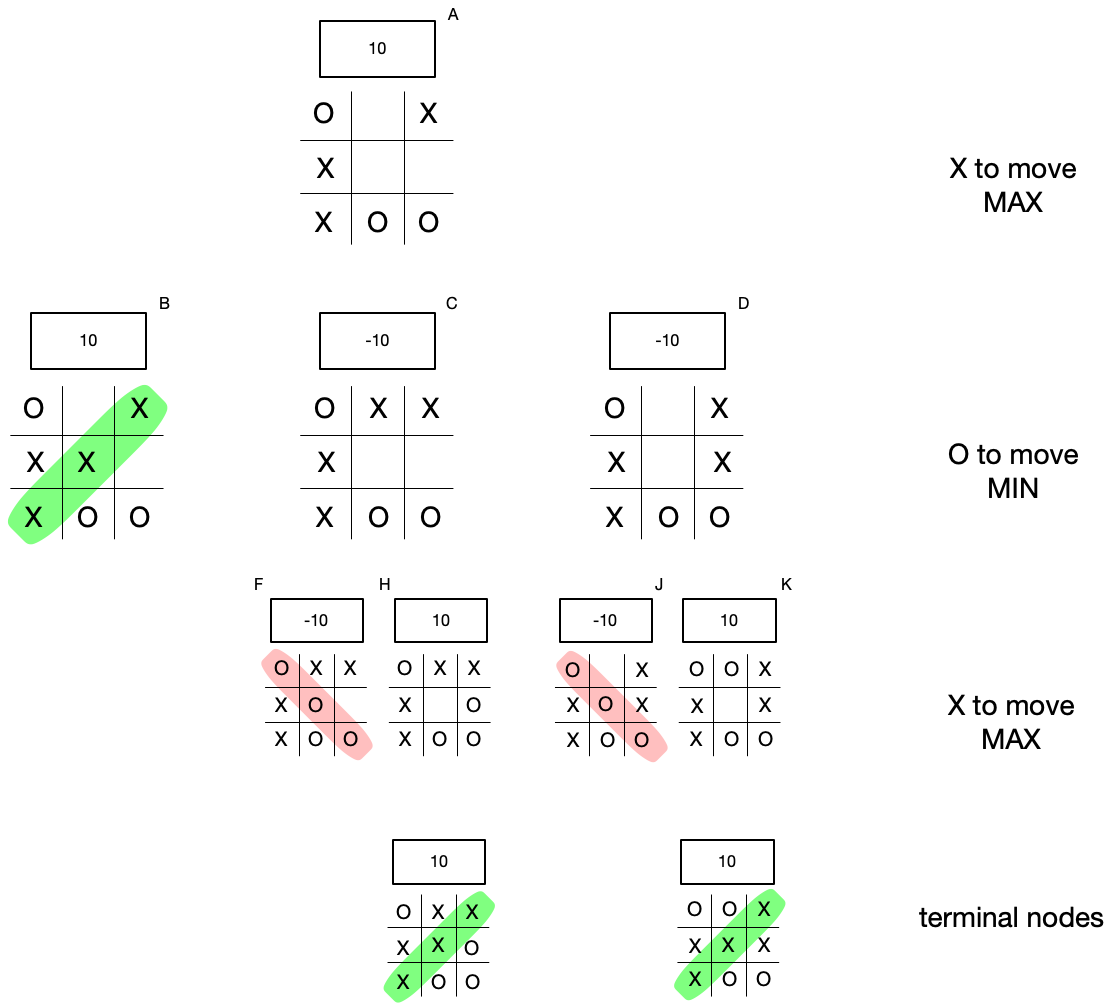
Notice what’s at work here. Even though in the two rightmost subtrees of the root, there are paths to wins for “X”, none of these wins can be reached because “O” will choose a move that minimizes the score, effectively blocking “X”’s path to victory.
Here’s the final result, showing how we have calculated “X”’s best move.
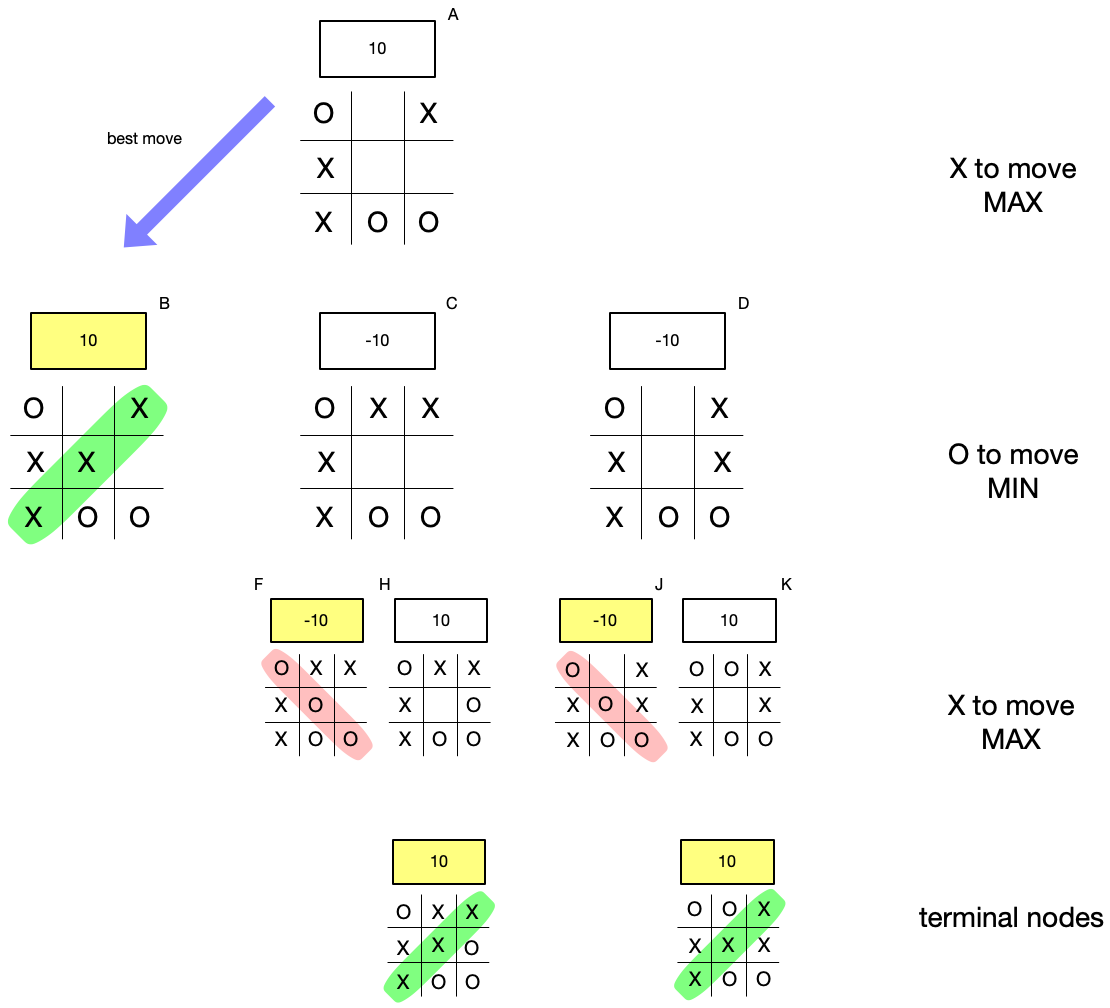
We call this algorithm “minimax” because it takes into consideration alternating moves by maximizing and minimizing player respectively.
Size and depth
Now, in the case of tic-tac-toe, we can construct the entire game tree. At the start of the game, “X” has nine possible moves. When it’s “O”’s first move, there are only eight possible moves. So the branching factor decreases by one with each move.
This means there are 9! = 362,880 possible game states, if we don’t consider reflection and rotation. If we do take reflection and rotation into account there are only 5,478 distinct game states. Thus, it’s no big deal to load the entire game tree into memory for tic-tac-toe.
With more interesting games, this is not possible. For example, there are something on the order of 10^{120} possible game states in chess. Go is even worse! Go has over 10^{170} possible game states on a full-sized 19 \times 19 go board.

So what’s to be done in cases like this where it’s literally impossible to represent all possible game states in memory? We limit the depth of the tree. This means that we must give static evaluations to non-terminal nodes at the depth limit and then apply minimax back to the root (current state) for whichever player is to move next. We call the evaluation of non-terminal nodes heuristics. The meaning of “heuristic” is different in this context than what we’ve seen with \astar and \idastar. It’s not an estimated distance from goal. Rather it’s an estimate of the maximin value for the player in question. The key point it that it’s an estimate.
In most interesting games,
- it’s not possible or it’s highly impractical to represent all possible moves from the current state to all reachable terminals in memory,
- we construct a depth-limited portion of the tree dynamically, based on the rules of the game (“legal” moves), and
- we compute an estimated, heuristic value for non-terminal nodes at the specified depth.
The trade-off here is time and space against the level of play. The deeper we can go into the game tree, generally the more accurate are our estimates, and thus, better moves are chosen resulting in stronger play.
The fact that we must limit tree generation means that we have an interesting problem called the “horizon problem.” It may be the case that a really great move or devastating trap exists just beyond the horizon of what’s been constructed. We’ll see how to deal with this later.

For now, let’s just work through a few problems to make sure we understand the mechanics of the minimax algorithm.
Some problem instances
First, remember that the entire game tree doesn’t exist in memory from the outset. We generate the tree as we go, using the rules of the game to determine successor states of a given node. That means we cannot evaluate a node until it has been generated. (This is crucial for understanding \alpha–\beta pruning, which we will see soon.)
Let’s say we have a game in which each game state has exactly two successors (children). Furthermore, let’s say our game engine is configured to search the game tree to a depth of three. Don’t forget, that “search” means generate children as needed as we go. When we reach the specified depth, we evaluate the resulting nodes.
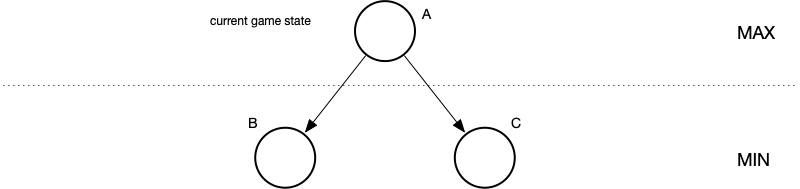
So we start from the current game state (labeled “A”).

We expand to depth one, by determining successor (child) states based on the rules of the game.
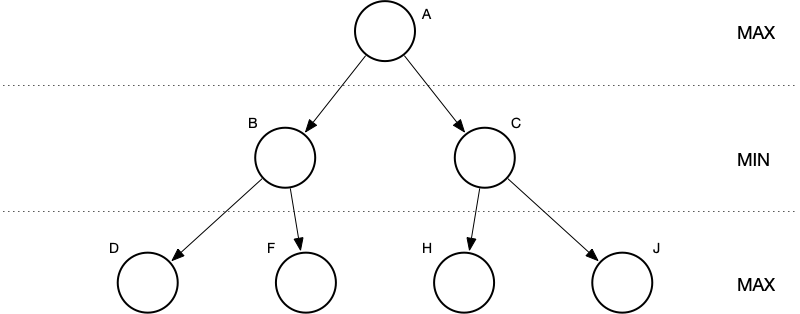
Then we expand to depth two.
Then we expand to depth three.
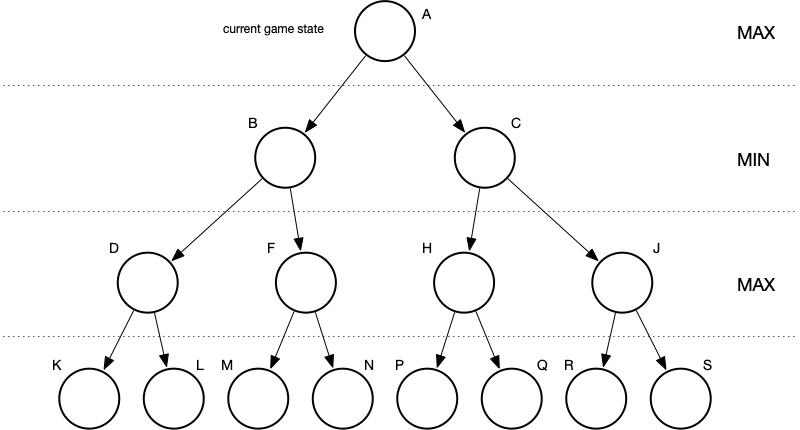
At this point, we’ve reached the specified depth limit (d = 3) and we evaluate the nodes at that depth.
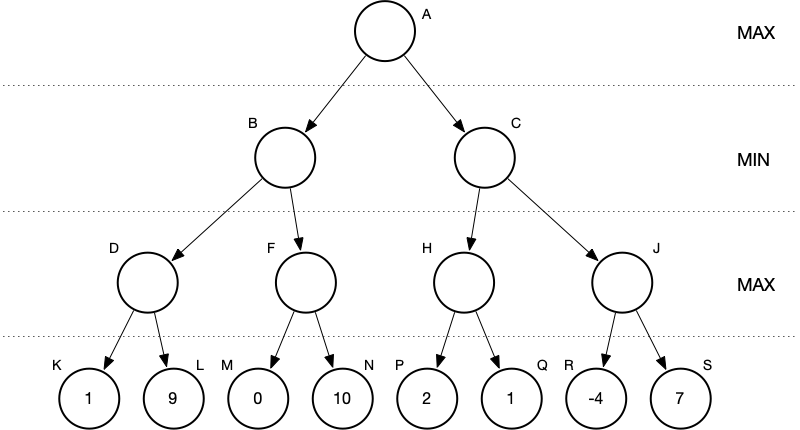
Then we proceed back toward the root. Nodes which correspond to a move by MIN receive the minimum value of their children. Nodes which correspond to a move by MAX receive the maximum value of their children.
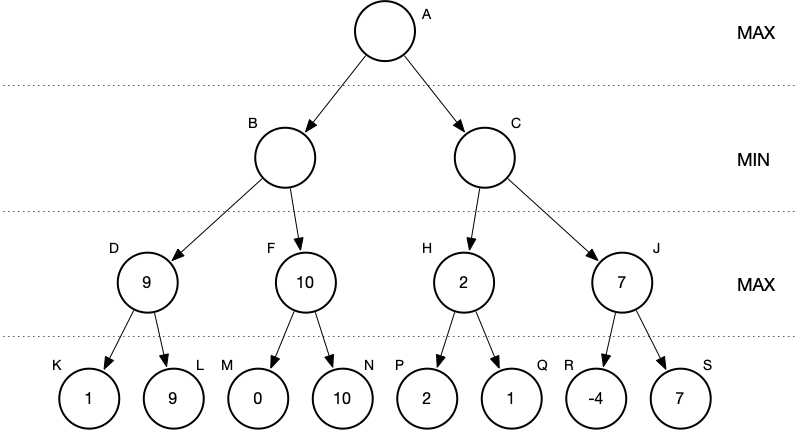
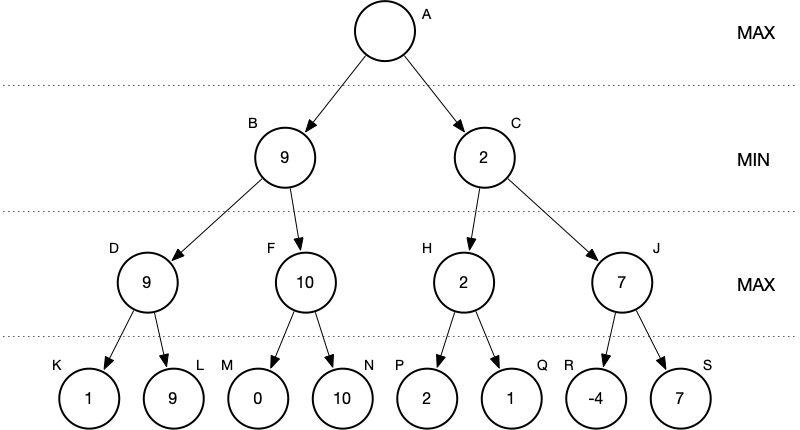
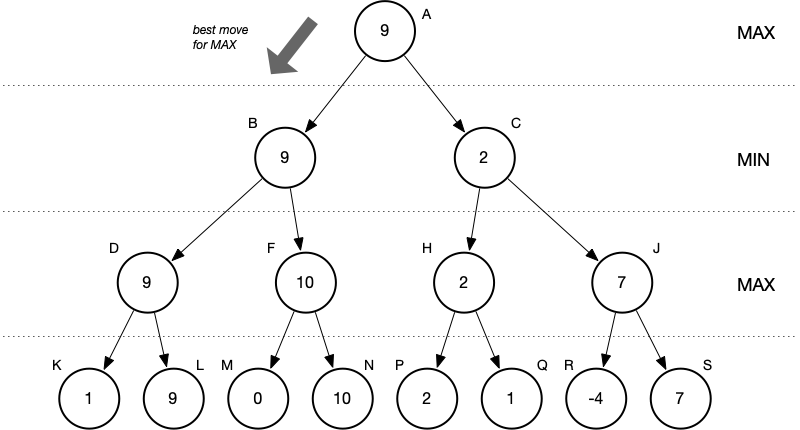
We reach the root, which corresponds to MAX’s next move, and choose the larger of the two values of child nodes. Now we know what MAX’s best move is—it corresponds to choosing the game configuration represented by the left child.
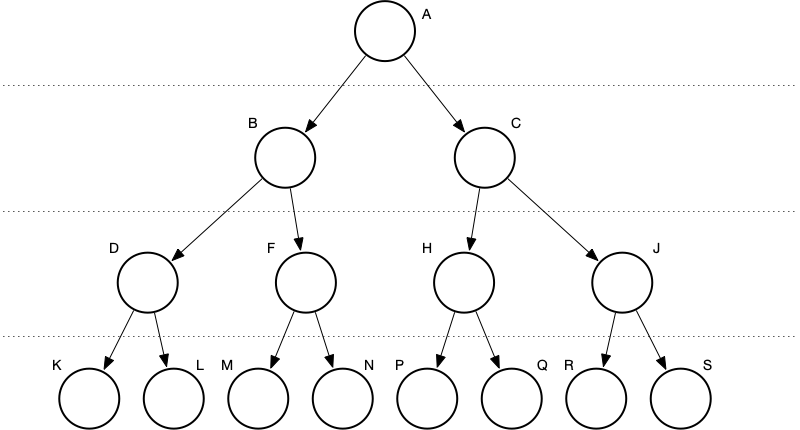
Here are a two you can do on your own to test your comprehension. We’ll use the same node labels, but keep in mind that we’ll treat depths differently depending on whether it’s MIN’s move or MAX’s.
MAX to move. At depth of three, we determine the following static evaluations: K = 5, L = -3, M = -2, N = 0, P = 7, Q = 1, R = 0, S = -2. Determine MAX’s best move. Is it the game state represented by node B or by node C?
MIN to move. At depth of three, we determine the following static evaluations: K = 0, L = -2, M = 6, N = 9, P = -7, Q = 3, R = 9, S = 11. Determine MIN’s best move. Is it the game state represented by node B or by node C?
Copyright © 2023–2026 Clayton Cafiero
No generative AI was used in producing drafts of this material. This was written the old-fashioned way. AI was used to rewrite existing pseudocode in LaTeX to produce standalone *.tex files for rendering, and for revisions toward satisfying WCAG 2.1 AA-level accessibility standards as required by UVM policy. AI may also have been used to proofread selected human-written prose. Claude 2.1 with model Sonnet 4.6. Revisions, if any, were performed by the author. AI was not used in generating any code whatsoever. All code samples and starter code are by the author only.