Introduction, history, and overview

Introduction
From SOC: “Introduction to computer system organization including performance, assembly language, machine-level data representation, arithmetic for computers, processor datapath control, memory, and input/output. Includes significant semester project.”
What is “computer organization”?
Computers aren’t monolithic or amorphous blobs of stuff—they have structure. They include different components which serve different purposes. Among these components are a central processor unit (CPU); volatile and non-volatile memory; input devices such as keyboards, touch screens, cameras, track pads, and microphones; output devices such as a monitor or speakers; interfaces which allow connection to other devices; and so on. Computer organization gives an account of the structure and components of a computer, how they are connected, and how they interoperate.
Personal computing devices
- desktop and laptop computers
- smartphones
Servers and supercomputers
- VACC & Deep Green here at UVM
- database servers
- web servers
- scheduling systems
- etc
Embedded systems
- automobiles
- smart appliances
- all manner of gadgets
Each type of computer will have somewhat different organization, depending on its scope and purpose, but there are many common components and principles of organization.
We can classify computers in a different way…
General-purpose computers
Personal computers (laptop and desktop) fall into this category. In the case of portable devices, they tend to have lots of peripheral components built-in (microphones, speakers, cameras, etc.) In portable and non-portable cases, they tend to have many different ways to connect with other, external devices.
Specialized computers (embedded or otherwise)
Specialized computers tend to have fewer components and oftentimes less memory, etc. These machines are designed to do one thing well, so designers and engineers determine requirements and include only what is necessary for the device to do its job.
Check-in
Apart from built-in peripherals on portable devices, what might be other characteristics of general-purpose computers?
- more RAM
- hard-disk or solid-state disk storage
- (see what students come up with)
What are some external peripheral devices one might connect to a computer?
- printers and scanners
- cameras and microphones
- audio interfaces
- external speakers, including Bluetooth speakers
(We’ll talk about USB, Bluetooth, and other interfaces later.)
What are some other applications of embedded systems (apart from automotive and smart appliance)?
- robots
- avionics and astrionics
- telecommunications
- medical imaging
- IoT
- (see what students come up with)
Guess: What percentage of microprocessors manufactured are used in embedded systems rather than personal or general-purpose computers?
Answer: 98% (2009; Wikipedia)
Why is computer organization relevant?
Apart from demystifying what goes on inside a computer, an understanding of computer organization is essential for any software developer.
An understanding of computer organization
- helps us design and build applications that work within the restrictions of available resources;
- allows us to make intelligent decisions regarding the trade-offs we encounter, inevitably, when writing programs;
- allows us take effective steps toward optimizing performance—if we understand the infrastructure upon which our programs run, it eliminates guesswork and trial-and-error;
- allows us to debug more effectively;
- allows us to work with events—mouse or trackpad clicks, keystrokes, etc.—and write programs what respond to such events;
- provides us with a mental model for understanding concurrency and parallelism—for reasoning about race conditions, atomic operations, and memory;
- allows us to bridge software and hardware domains; and
- gives us an understanding of layers of abstraction and the interfaces between them—from bare metal on up.
Data and instructions
Understanding of how data are represented allows us to work more efficiently with data. This includes using memory resources wisely, but also allows us to transform data more effectively. (bitwise ops)
We want to use abstraction and high-level languages to write computer software, but how does code written in Java, Python, or C get executed on a computer? Computers don’t “understand” these languages. Instead, all code on a computer is binary—consisting of only zeros and ones. Each CPU architecture has its own instruction set, also in binary. How do instructions and data that humans can read get turned into the ones and zeros that computers understand? That is, how can software be made to interact with hardware?
History
Much has changed since the first computers were built in the 1940s, in terms of capability, design, and organization.
Things that not so long ago were science fiction are now commonplace—supercomputers, smartphones, wearables, virtual reality, and so on.
- How is such progress possible?
- What is it about computers that has afforded such incredible progress in so short a time?
- What has changed in terms of how computers are organized?
- How have individual components been improved to bring about these changes?
The vast majority of computers use what’s called the von Neumann architecture (after John von Neumann—mathematician, physicist, computer scientist, and engineer).
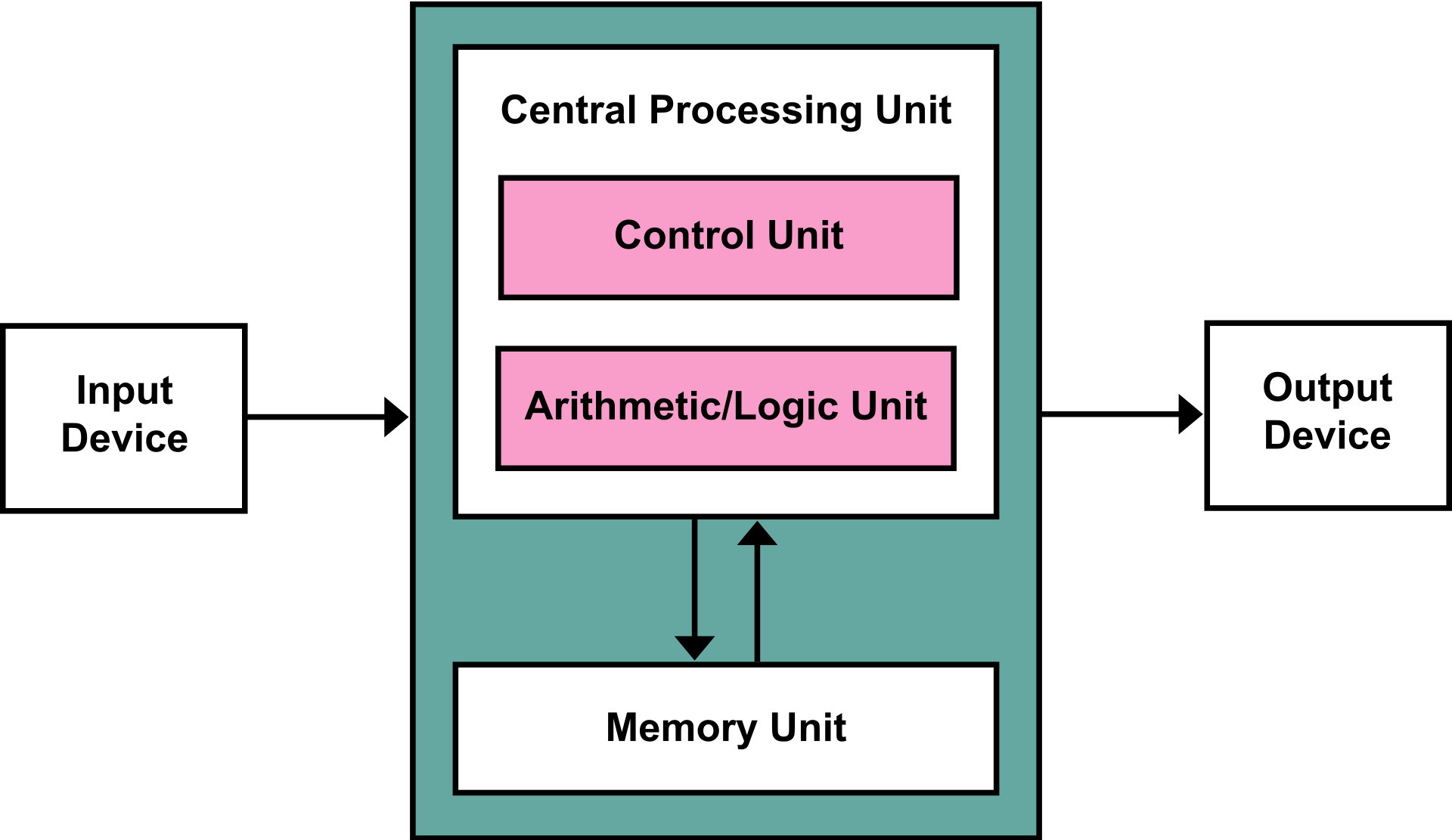
von Neumann is often associated with the ENIAC, the first programmable, electronic, general-purpose digital computer, which was commissioned in 1945 (ENIAC: Electronic Numerical Integrator and Computer). However, he only consulted on the project. The ENIAC was designed by John Mauchly and J. Presper Eckert, and did not use a von Neumann architecture, largely because the ENIAC did not support stored program instructions (software). Rather it was programmed using a plugboard. Every time a new computation was needed the plugboard needed to be repatched and configured.

Nevertheless, the ENIAC provided von Neumann plenty to think about, and his ideas were first presented in his report “First Draft of a Report on the EDVAC” (the EDVAC being a planned successor to the ENIAC; EDVAC is an acronym for Electronic Discrete Variable Automatic Computer). The EDVAC was to become the first, fully-programmable computer, with the ability to store and load programs from memory. von Neumann’s report was not without some controversy, and many on the ENIAC team felt that von Neumann had presented many of their ideas as his own. But fame begets fame, and von Neumann was justifiably famous, and so now this architecture bears his sole name, for better or worse. There is no question, however, that his contributions were pivotal.
What’s distinctive about the von Neumann architecture? Originally, physically, this was an architecture which included a central arithmetic unit, a central control unit, volatile memory, non-volatile memory (external), and a means of transferring data between components and (possibly) external devices. This architecture made possible stored programs, eliminating the need for the plugboard to program the computer. Programs could be written and stored in non-volatile memory, and then retrieved and loaded into volatile memory as needed for execution. Another characteristic feature of the von Neumann architecture is that means of transferring data between components. Nowadays this is called a data bus, or just bus for short.
Let’s compare this with another early architecture which is still in use today.
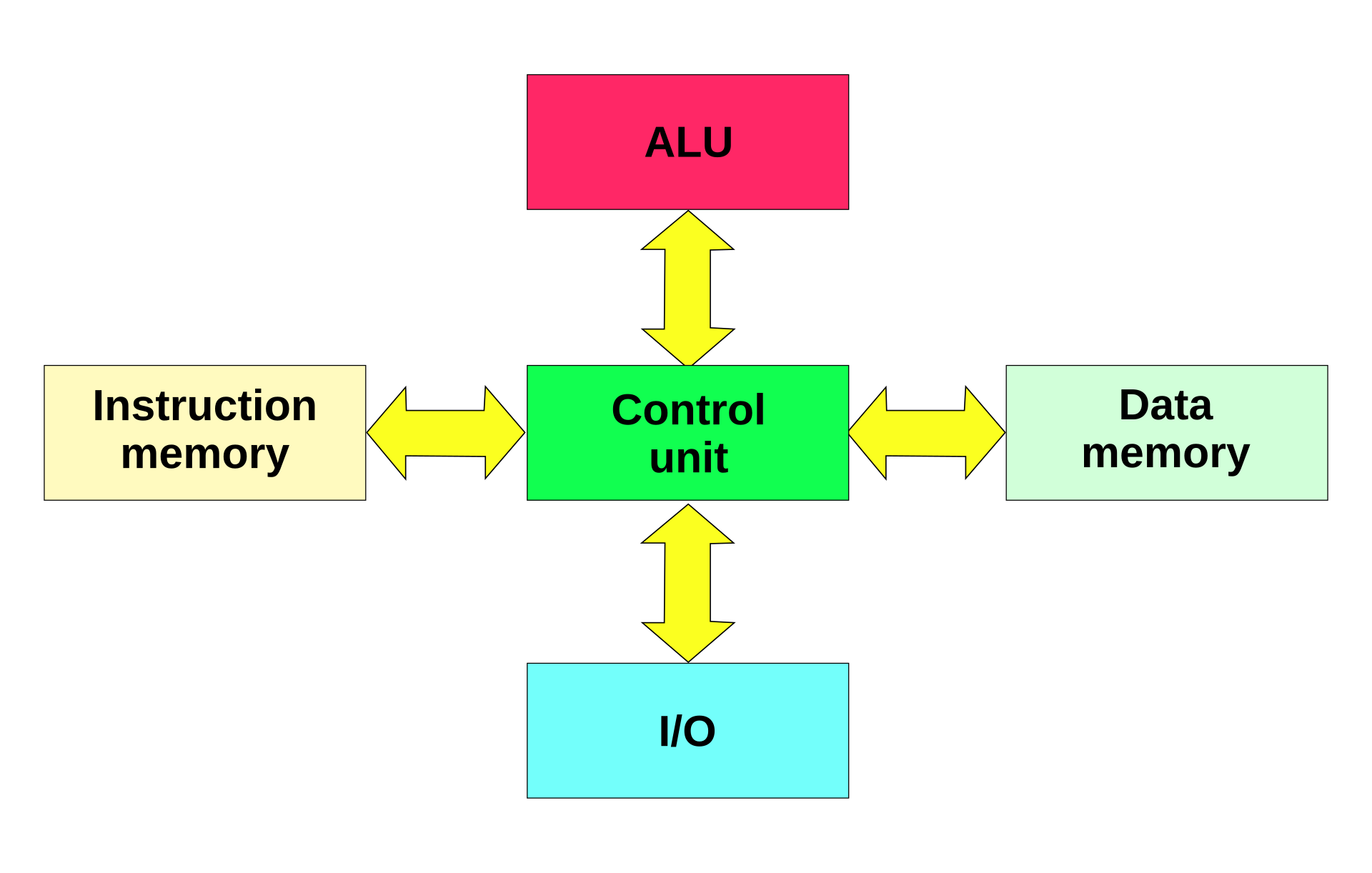
The big difference here is that the Harvard architecture distinguishes data memory and instruction memory, and lacks a common, shared bus.
Eight Great Ideas in Computer Architecture
(What follows under this heading is based in part on P&H, section 1.2.)
1. Design for Moore’s law.
In 1965 Gordon Moore (a founder of Intel) predicted that the number of transistors on a microchip would double every two years. There are limits, of course, but so far his prediction has been pretty solid.
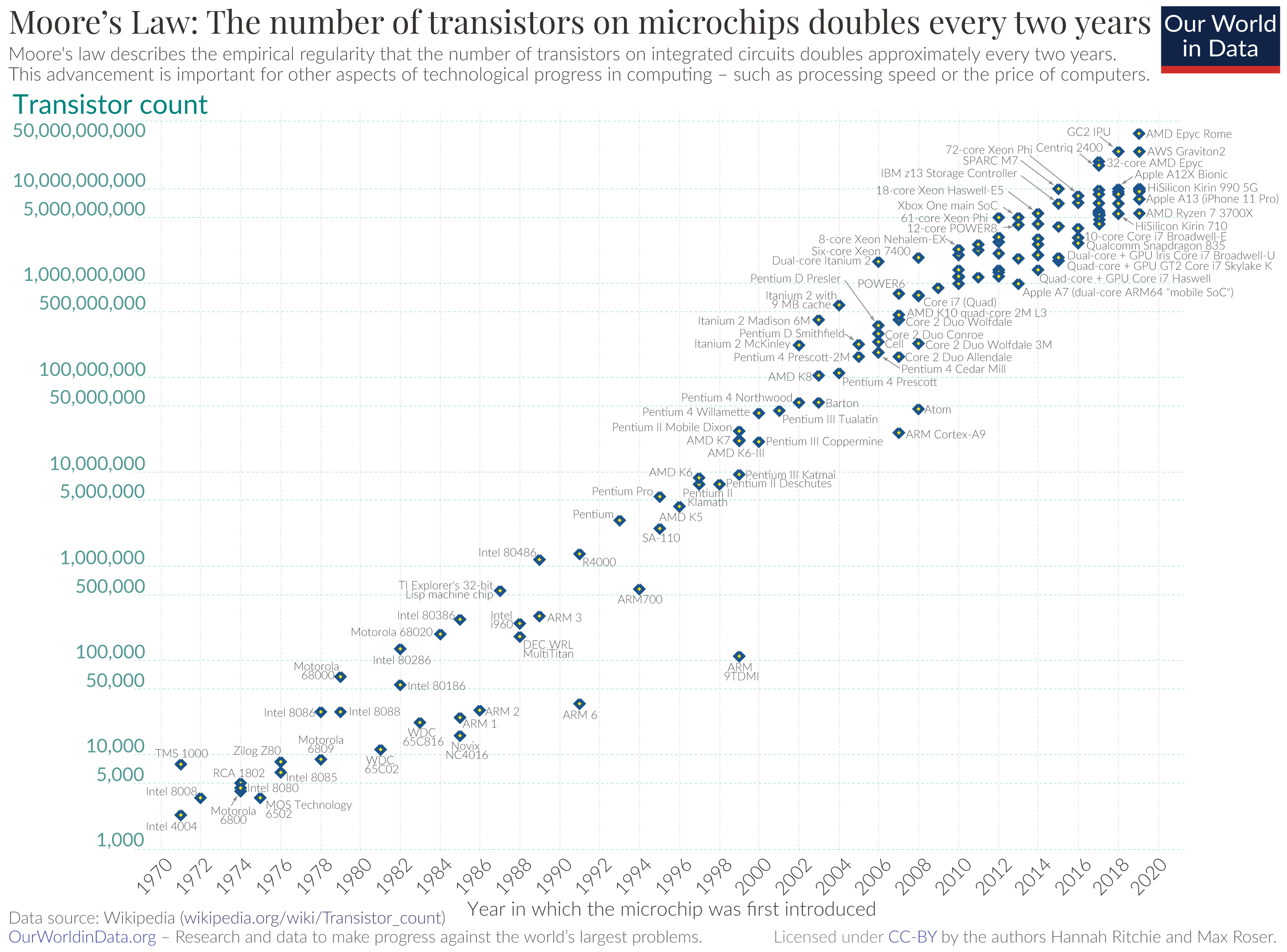
What this means is that there’s been a predictable trend of increasing processor power. The implications for designers of computers is that this forecasted increase should should be taken into account. For example, let’s say that in 2000 we started design of a new computer, and that the memory and other requirements were based on technology available in 2000. By the time the computer was ready for production and shipment, it’d be obsolete—with all kinds of built-in bottlenecks and unnecessary constraints. Accordingly, designers of computers—whether desktop or mobile devices, or embedded systems—must take Moore’s law into consideration. This isn’t easy. As P&H suggest, it’s like aiming at a moving target. However, if we don’t do our best to anticipate increases in processor power, then we risk designing machines that don’t take advantage of what the additional processor power has to offer.
Moreover, with increasing transistor density has come the ability to use larger amounts of memory. There a number of interesting cases in which machines were designed that couldn’t effectively take advantage of the full memory address space available. We’ll take a brief look at the Intel 286 and 386 processors and the Motorola 680000 as examples a little later in the course.
2. Use abstraction to simplify design
Abstraction is at the core of computer science. Using abstraction to simplify design is a tremendously powerful concept, but what, exactly does this mean?
Consider this. An Apple M2 chip has 20 billion transistors. Clearly it makes no sense to try to write programs that control each of these individually—no one would live long enough to complete a single program! Instead, we take advantage of different levels of abstraction and interfaces for each of these levels. This allows us to write programs in high-level (abstract) languages that run on chips with 20 billion transistors. Indeed, there is a hierarchy of abstraction:
- the physics of semiconductors and electricity;
- digital (Boolean) logic and logic gates;
- microarchitecture: datapaths, registers, arithmetic logic units, control units, and memory interfaces within a CPU;
- instruction set architecture;
- machine language and assembly;
- system software and the operating system kernel;
- high-level languages;
- application software; and
- the user interaction layer.
Each layer is more abstract, and hides implementation details of lower levels. (Some might find it strange that information hiding is crucial, but it is.) When we’re writing a program in Java, we don’t have to worry about how the CPU is fetching and executing individual instructions or how registers are used, for example.
Without abstraction, computers would be impossible.
3. Make the common case fast
When it comes time to optimize performance, it makes sense to optimize the most commonly performed operations before moving on to anything else. Without experimentation and analysis to determine the most common cases, we don’t know how to prioritize our efforts. In the worst case, we could optimize the wrong things, and leave our code and machines to struggle with common, frequently-used operations.
Other great ideas
Other great ideas listed in P&H are great—performance via parallelism (4), performance via pipelining (5), performance via prediction (6), hierarchy of memories (7), and dependability via redundancy (8). However, we’ll defer discussion of these until we have more of a foundation.
External resources (Wikipedia)
- ENIAC
- Harvard architecture
- von Neumann architecture
- First Draft of a Report on the EDVAC
- EDVAC
- Moore’s law
- Apple M2 press release
© 2025 Clayton Cafiero.
No generative AI was used in writing this material. This was written the old-fashioned way.