A brief introduction to databases with SQLite

We have seen how to read data from a file, either in unstructured text or CSV format, and how to write data in these formats. We’ve also seen how to read and write JSON. In this chapter we’ll see how to use a database with Python.
There is a bewildering variety of databases, and a great many special-purpose databases, but the most widely used are relational databases and “NoSQL” databases. Common relational databases include Oracle, MySQL, PostgreSQL, MariaDB, Percona, and Microsoft SQL. Common NoSQL databases include MongoDB, Cassandra, Redis, and DynamoDB. In this appendix, we’ll learn about a simple relational database that has native support built in to Python: SQLite.
SQLite (usually pronounced “sequel-ite”) was first released in 2000 and has had native support in Python since 2006 through Python’s sqlite3 module.
The “SQL” you see in many of these names is short for structured query language. There are many dialects of SQL but they all share many common characteristics. SQLite is one such dialect, and true to its name, SQLite is a lightweight, minimal database solution.
This is not intended as a complete introduction to relational databases. We will not cover topics such as referential integrity, triggers and cascades, relational calculus, varieties of joins, database normalization, object-relational mappers (ORMs), database administration, or security. This will be a minimal introduction.
What is a “database”?
What exactly is a database? Usually what we mean by this (and certainly what we mean here) is a structured repository of data, organized into tables, managed by a database management system (DBMS). We don’t edit the files of a database directly (and in some systems there can be a great many). Instead we let the DBMS do that for us, and we interact with the database through queries and commands specific to the particular system. Here we will use SQLite.
SQLite with Python
A relational database consists of one or more tables. Like a CSV table, a SQLite table has rows and columns. Unlike a CSV table, a SQLite table includes specification of data type, and (perhaps) other constraints. The structure of a database is called a schema.
When we use SQLite with Python, it’s SQLite that’s doing all the work. That’s the database engine. Python provides us with a nice interface allowing us to write code in Python that “talks to” SQLite. This affords us many conveniences, but it doesn’t eliminate the need to write our queries in SQL. So this will take some getting used to. SQL is an entirely different language—unlike Python in almost every respect. To keep things straight: SQL code will appear as string arguments passed to functions provided by Python’s SQLite interface, sqlite3. The surrounding code is Python. So you’ll see SQL queries as arguments in Python function calls, but never the other way around.
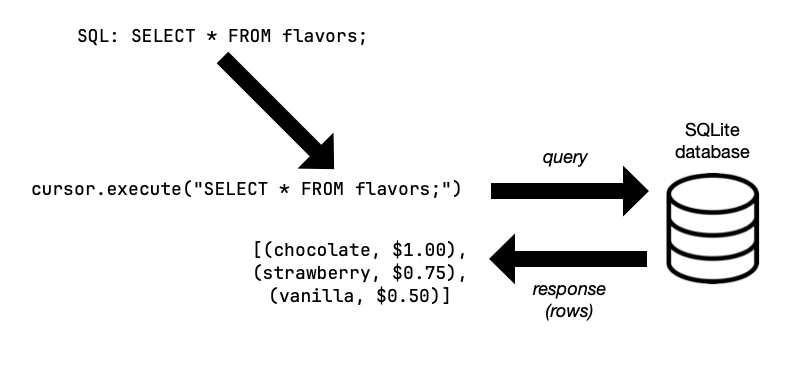
Let’s say we were creating a database of student clubs on campus. Here are a few (from UVM’s clubs directory):
- African Student Association
- Agriculture Club
- Alianza de Latines
- American Sign Language Club
- Anthropology Club
- Archery Club
- Art Club
- Asian Student Union
Let’s say we wanted to store the name of the club, the year the current by-laws were approved, and the current president. (I’m going to make up some names and numbers here.)
| Name | By-laws | President |
|---|---|---|
| African Student Association | 2020 | Amy Adeoye |
| Agriculture Club | 2019 | Hortense Greenthumb |
| Alianza de Latines | 2021 | Ernesto Ortiz |
| American Sign Language Club | 2017 | Marie Austyn |
| Anthropology Club | 2022 | Ken Korey |
| Archery Club | 2023 | Bill Tell |
| Art Club | 2020 | Julia Fish |
| Asian Student Union | 2021 | Michiko Itatani |
If we wish to make a database table to represent such data, we’ll need to specify the column names and the data type for each column. Clearly name and president are strings, and year is an integer.
So how do we create a database table? While a SQLite database consists of files on your computer’s disk or solid-state drive, we don’t create or edit these files directly—the database engine does this for us. So instead, we create a connection to a database, and then write a query to create the table for us. What we supply is a definition of the table, called a table schema.
We’ll need two things to start, a connection to the database, and a database cursor.
>>> import sqlite3
>>> cnx = sqlite3.connect("clubs.db")
>>> cursor = cnx.cursor() First we import sqlite3. This is a standard Python module, included with your Python distribution—there’s nothing to install.
Then we create a connection, giving the name of the database "clubs.db". The .connect() function opens a connection to the specified database. If the specified database does not exist, it will create the database for you. The .db file extension isn’t strictly necessary but it’s good practice to include it. Notice that we assigned the database connection to a variable named cnx. (con, conn, and connection are also commonly-used names for this.)
Then we get a cursor into the database. A database cursor is like a pointer into your database which is used to traverse the database, and to retrieve and manipulate records. Notice that we assigned the cursor object to a variable named cursor.
Now we’re ready to create our table. Here’s where we’ll write in SQL. We’ll write SQL to construct our table, and pass this to the cursor for execution. Notice that the script is a multi-line string. If we have multiple SQL statements, we separate them with semicolons. If we have a single statement, termination with a semicolon is optional. Like Python, SQL isn’t particularly fussy about single- or double-quotes for strings. SQL keywords appear in UPPER CASE. Tokens in lower case (without quotation) are identifiers. Identifiers here are names of tables and names of columns within tables.
>>> cursor.execute("""
... CREATE TABLE club (
... name TEXT PRIMARY KEY,
... year INTEGER,
... president TEXT
... );
... """
... )
...
<sqlite3.Cursor object at 0x1025b6f40>
>>> cnx.commit() Let’s walk through this. We’d previously created a cursor with cursor = cnx.cursor(). Here we passed this SQL to the cursor for execution: The last bit is what’s emitted at the prompt. When we call cursor.execute() it returns itself (that’s what we see at the prompt; you may ignore this). The reason it returns itself, is to facilitate method chaining, but we won’t futz with that here.
CREATE TABLE club (
name TEXT PRIMARY KEY,
year INTEGER,
president TEXT
); This was wrapped in triple double-quotes (for a multi-line string). This tells SQLite to create a table named club (it’s considered good style to name tables with singular nouns). name TEXT PRIMARY KEY tells SQLite to add a column in the table, called name, and that this column will hold text (string) data. PRIMARY KEY tells SQLite that entries in this column must be unique (can’t have two clubs with the same name). KEY has a different meaning in SQL than it does with Python dictionaries. cnx.commit() tells SQLite to commit the change to disk storage.
After this has been executed, we can check the resulting change in the database. Here we’ll ask for information about the newly-created table.
>>> result = cursor.execute("PRAGMA table_info(club);")
>>> for column in result.fetchall():
... print(column)
...
(0, 'name', 'TEXT', 0, None, 1)
(1, 'year', 'INTEGER', 0, None, 0)
(2, 'president', 'TEXT', 0, None, 0)Again, there’s a lot going on here, so let’s take it in chunks.
PRAGMA table_info(club); PRAGMA commands (from “pragmatic”) are SQLite-specific commands used to get information about the structure of the database or tables, or to inspect or alter configuration information. (They’re generally not used in production.) Here we’re using the PRAGMA command table_info() to get information about a particular table (club).
Notice that we’ve assigned the result to a variable named result (which is a cursor object). Then we call .fetchall() on this object to get records containing information about individual columns within the table, club. When we iterate over this, we get three tuples, each describing one of the three columns in the table. Each tuple has six elements:
- the column number (zero-indexed),
- the column name,
- the datatype of the column,
- whether or not a null (empty) value is permitted for the column,
- a default value if any (in this case all
None), and - whether the column is a primary key (1 if a primary key, 0 otherwise).
Consider why each row is represented with a tuple. It should make sense to say that in a very real sense, a row in a database table is a tuple. Not a Python tuple, of course, but think about what makes a tuple a tuple, in the abstract sense. A tuple is an ordered collection of objects. You can’t rearrange the elements of a tuple. You can’t remove an element; you can’t add an element. Database rows are like this.
Now that we’ve confirmed the table has been created, let’s add some records. For this we use an INSERT statement and cnx.commit().
>>> cursor.execute("""
... INSERT INTO club (name, year, president)
... VALUES ('African Student Association', 2020, 'Amy Adeoye'),
... ('Agriculture Club', 2019, 'Hortense Greenthumb'),
... ('Alianza de Latines', 2021, 'Ernesto Ortiz'),
... ('American Sign Language Club', 2017, 'Marie Austyn'),
... ('Anthropology Club', 2022, 'Ken Korey'),
... ('Archery Club', 2023, 'Bill Tell'),
... ('Art Club', 2020, 'Julia Fish'),
... ('Asian Student Union', 2021, 'Michiko Itatani')
... """)
<sqlite3.Cursor object at 0x1025b6f40>
>>> cnx.commit() Again, there’s a lot going on here, so let’s take it step-by-step. INSERT and certain other operations involve transactions. Transactions give us ACID. ACID is an acronym for atomicity, consistency, isolation, and durability.
Atomicity is a guarantee that either an entire transaction succeeds or it doesn’t. It’s never the case that part of a transaction succeeds but another part does not. Imagine a bank transfer, for example a transfer from your Venmo account to your bank. This transaction has two parts: a debit (deduction) from your Venmo account, and a credit (deposit) to your bank account. Somebody would be unhappy if only one part of this transaction succeeded and the other failed. With an assurance of atomicity, this can’t happen. Either the transfer succeeds, or it doesn’t.
Consistency is a guarantee that before and after a transaction has taken place, the database is in a valid state. For example, if a certain constraint is required by our database, consistency ensures that this constraint is satisfied before and after each transaction. If we try to insert a record without the required values, the transaction fails.
Isolation is a guarantee that one transaction cannot affect another.
Durability is a guarantee that once a transaction has been committed, the data will persist in the database, no matter what—even if at some point the system crashes.
When we issue an INSERT, a transaction is opened automatically. To close the transaction, we call .commit(). SQLite has an auto-commit mode (and you can check this with the attribute cnx.autocommit), but it’s good practice to call .commit() (but I may not explicitly use this in every example).
If there was even a single error in the INSERT statement above, the entire transaction would fail, and the database would be left unchanged in a valid state. If the transaction succeeds, we’re guaranteed that all eight records representing clubs are saved.
Now, let’s check the database. Databases wouldn’t be very useful if we couldn’t retrieve data from them. Here’s a simple query to retrieve all records in the club table.
>>> result = cursor.execute("SELECT * FROM club")In SQL, * means all, so "SELECT * FROM club" means select all rows in the table club. To access these records, we can use .fetchall().
>>> result.fetchall()
[('African Student Association', 2020, 'Amy Adeoye'),
('Agriculture Club', 2019, 'Hortense Greenthumb'),
('Alianza de Latines', 2021, 'Ernesto Ortiz'),
('American Sign Language Club', 2017, 'Marie Austyn'),
('Anthropology Club', 2022, 'Ken Korey'),
('Archery Club', 2023, 'Bill Tell'),
('Art Club', 2020, 'Julia Fish'),
('Asian Student Union', 2021, 'Michiko Itatani')]Whenever we get a row of data from SQLite, the default result is a tuple, as you see in the example above. Sometimes a tuple is fine, but there are other options. Why consider other options? Well, for one, with a simple tuple, we can’t refer to columns within a row by name, we have to use indexed reads to select values in specific columns.
Python’s sqlite3 allows us to specify a row factory that is used to construct objects retrieved by a query. Again, by default, rows are returned as tuples. Other options include sqlite3.Row objects, named tuples, dictionaries, Python dataclasses, or custom classes. We won’t get deep into object-oriented programming here (OOP), but let’s explore the other options so we can evaluate the pros and cons, and give you some idea of how we’d choose the right tool for a given job.
Generally, to choose a different representation of a row, we supply a factory method to the SQLite connection. SQLite then uses this factory method to construct output in the desired form. Factory methods are a common approach to constructing objects—they’re used in all kinds of programming. A factory method constructs objects according to some type or specification. The first we’ll investigate is sqlite3.Row.
sqlite3.Row will give us something akin to a dictionary, in which we can refer to columns in a row by their name. We can tell SQLite to use this factory thus:
>>> cnx.row_factory = sqlite3.Row Notice what we’re doing here. sqlite3.Row is the name of a function and by assigning this to cnx.row_factory we’re telling the database connection which function to call when constructing rows. If we want our cursor object to use this, we must instantiate it after setting the row factory.
>>> cnx.row_factory = sqlite3.Row
>>> cursor = cnx.cursor() # NOW cursor knows to use the factory Now, when we get results of a query, they’re of type sqlite3.Row, not plain-vanilla tuples—and these objects have keys for their fields.
>>> result = cursor.execute("SELECT * FROM club")
>>> for row in result.fetchall():
... print(f"{row['president']} is the president of the "
... f"{row['name']}.")
...
Amy Adeoye is the president of the African Student Association.
Hortense Greenthumb is the president of the Agriculture Club.
Ernesto Ortiz is the president of the Alianza de Latines.
Marie Austyn is the president of the American Sign Language Club.
Ken Korey is the president of the Anthropology Club.
Bill Tell is the president of the Archery Club.
Julia Fish is the president of the Art Club.
Michiko Itatani is the president of the Asian Student Union.That’s nicer than having to refer to the president column as row[2] and the name column as row[0].
Again, there are other options. For example, this is a great case for named tuples, so let’s see how we can used a named tuple here. For this, we’ll need to supply our own factory method to the database connection and then instantiate a new cursor object. First, let’s define a named tuple class for a club.
>>> from collections import named tuple
>>> Club = namedtuple('club', ['name', 'bylaw_year',
... 'president'])Now we need to define a factory method. Think about what would be needed: given a row as a tuple, construct a named tuple object from the row tuple. There’s a specific interface we must use so that SQLite can use the factory. Our method must take two arguments: a Cursor object and the tuple of row values. Our method should return an object which represents the given row.
Now, you might think something as simple as this would be OK:
>>> def club_factory(cursor, row):
... return Club(*row)
>>> cnx.row_factory = club_factoryand indeed this works as you’d expect.
>>> cursor = cnx.cursor()
>>> result = cursor.execute("SELECT * FROM club")
>>> for row in result.fetchall():
... print(row)
...
club(name='African Student Association',
bylaw_year=2020, president='Amy Adeoye')
club(name='Agriculture Club',
bylaw_year=2019, president='Hortense Greenthumb')
club(name='Alianza de Latines',
bylaw_year=2021, president='Ernesto Ortiz')
club(name='American Sign Language Club',
bylaw_year=2017, president='Marie Austyn')
club(name='Anthropology Club',
bylaw_year=2022, president='Ken Korey')
club(name='Archery Club',
bylaw_year=2023, president='Bill Tell')
club(name='Art Club',
bylaw_year=2020, president='Julia Fish')
club(name='Asian Student Union',
bylaw_year=2021, president='Michiko Itatani')Boom! How easy was that? Ah, but there’s a “gotcha” here. This solution only works for the club table. If we were to query the database regarding table structure as we did with PRAGMA table_info(club); this would fail! Why? Because this doesn’t return rows of club data. Few databases consist of a single table, and we’ll get to adding another table to our database soon. We need a more general approach—one that will work with any table, any query result. Here we’ll adapt a solution from the Python documentation (see: SQLite row factory).
When we issue a query like: cursor.execute("SELECT * FROM club"), we get the selected rows, but we can also inspect the cursor to get the row names. For this we use cursor.description. For each field in the query cursor.description will hold a tuple, the first element of which is the field name (even if no rows are returned).
>>> result = cursor.execute("SELECT * FROM club")
>>> for item in cursor.description:
... print(item[0])
...
name
year
presidentThis allows us to dynamically retrieve column names returned by any query. We can use this information to define a dynamic factory method for named tuples.
>>> def namedtuple_factory(cursor, row):
... fields = [] # to hold the field names
... for column in cursor.description:
... fields.append(column[0]) # get the field names
... # dynamically construct a named tuple class
... cls = namedtuple("Row", fields)
... # instantiate an object of this class
... return cls(*row) # use a splat, but see footnoteNow we can use this factory and it will work with any table or query result!
>>> cnx.row_factory = namedtuple_factory
>>> cursor = cnx.cursor() # get a new cursor to use factoryNow instead of referring to fields like this row['president'] we can use row.president.
>>> result = cursor.execute("SELECT * FROM club")
>>> for row in result.fetchall():
... print(f"{row.president} is the president of the "
... f"{row.name}.")
...
Amy Adeoye is the president of the African Student Association.
Hortense Greenthumb is the president of the Agriculture Club.
Ernesto Ortiz is the president of the Alianza de Latines.
Marie Austyn is the president of the American Sign Language Club.
Ken Korey is the president of the Anthropology Club.
Bill Tell is the president of the Archery Club.
Julia Fish is the president of the Art Club.
Michiko Itatani is the president of the Asian Student Union.If we wanted results as a dictionary we could construct a dictionary factory method. However, since named tuples have ._asdict(), we can always construct a dictionary if needed from a given named tuple. We might do that if we wanted to update the values of fields (say, there’s a new president or the bylaws have been updated). We’ll leave construction of a dictionary factory method as an exercise for the reader.
Here’s another relatively lightweight option that doesn’t involve full-fledged OOP: Python dataclass. The dataclass type is available via the dataclasses module, which is part of the standard Python distribution (no installation needed).
>>> from dataclasses import dataclass
>>> @dataclass # tell Python this is a dataclass definition
... class Club:
... name: str
... year: int
... president: str This creates a dataclass Club, with three fields: name, year, and president. Notice also that we specify the type of each field.
Unfortunately, creating a dynamic factory method that respects existing dataclass definitions would require more machinery than would be appropriate here (and isn’t more performant), so when we want to work with dataclass objects, we’ll construct what we need while iterating over query results. (We’ll see more on dataclass soon.)
Now let’s compare the possible ways we could construct objects to represent rows of data:
| feature | tuple |
sqlite3.Row |
namedtuple |
datatype |
|---|---|---|---|---|
| default | yes | no | no | no |
| index access | yes | yes | yes | no |
| key access | no | yes | no | no |
| named fields | no | no | yes | yes |
| immutable | yes | yes | yes | no |
| enforces type | no | no | no | yes |
| full control | no | no | no | yes |
Here “index access” means we can access elements by index like row[2]; “key access” means we can access elements by key like this: row['foo']; “named fields” means we can access by field name like this: row.foo; and “full control” means we can customize the behavior of objects and add custom methods (we’ll see a little more about this later). If we want something fast and easy, tuples are fine, but access by index isn’t ideal—especially if we have lots of columns. sqlite3.Row is also fast and easy, and gives us dictionary-like key access. sqlite3.Row is also robust to changes in schema or column orders. If we don’t mind defining our own namedtuple class or datatype class and corresponding factory methods, then these are good choices.
Selecting records by criteria
It’s often the case that we want to select specific records or even a single record based on certain criteria, and SQL allows us to do this. Let’s say we wanted to select all the clubs with by-laws adopted before 2020. We use a SELECT query with a WHERE clause.
>>> result = cursor.execute("""
... SELECT *
... FROM club
... WHERE year < 2020
... """)
>>> result.fetchall()
[Club(name='Agriculture Club', year=2019,
president='Hortense Greenthumb'),
Club(name='American Sign Language Club', year=2017,
president='Marie Austyn')]Notice something about SQL queries. We don’t have to tell SQLite how to find the records, apart from specifying the table and criteria. We don’t have to tell it to iterate over records in the table and to look in a particular column and perform a comparison, or anything like that. Instead, we tell SQLite what we want, and let SQLite figure out how to retrieve the appropriate records. This is what we call a declarative style of programming. In contrast, Python is an imperative language. To get the results we want we have to specify step-by-step instructions as to how to accomplish our goal. These are two very different programming paradigms.
Let’s write a query that selects a single record. Since name is a primary key, we know that the value for name uniquely identifies a single row in our table.
>>> result = cursor.execute("""
... SELECT *
... FROM club
... WHERE name = 'Anthropology Club'
... """)
>>> result.fetchone()
Club(name='Anthropology Club', year=2022, president='Ken Korey')Again, let’s unpack this. Here we have a SELECT query. The WHERE clause targets the single record with name 'Anthropology Club'. Notice that in the query = serves as a comparison operator (unlike Python’s ==). Also, notice that since we know we’ll have only one record, we can use .fetchone().
You might ask: What happens if there is no matching record or records for some criteria? Good question. The query succeeds, but we get an empty result.
>>> result = cursor.execute("""
... SELECT *
... FROM club
... WHERE name = 'Bongo Drumming Circle'
... """)
>>> result.fetchone()
>>>or
>>> result = cursor.execute("""
... SELECT *
... FROM club
... WHERE year > 3000
... """)
>>> result.fetchall()
[]Adding a new table
Now let’s create a table for club members and see how to join tables.
It wouldn’t make sense for us to include all the members of a club in the club table, and it’s not entirely clear how we’d do it anyway. A new table makes sense, because members of clubs (people) have different properties than clubs themselves. Let’s create a table with some club members.
>>> cursor.execute("""
... CREATE TABLE member (
... club_name TEXT,
... given_name TEXT,
... surname TEXT,
... email TEXT,
... );
... """)
...
>>> cnx.commit()Now let’s insert some records.
>>> cursor.execute("""
... INSERT INTO member (club_name, given_name,
... surname, email)
... VALUES ('Agriculture Club', 'Hortense',
... 'Greenthumb', 'hgreenthumb@uvm.edu'),
... ('Agriculture Club', 'Travis', 'Wilbury',
... 'tqwilbury@uvm.edu'),
... ('Agriculture Club', 'Richard', 'Mason',
... 'rymason21@uvm.edu'),
... ('Agriculture Club', 'Flora', 'Landis',
... 'ftlandis@uvm.edu'),
... ('Agriculture Club', 'Lillian', 'Valley',
... 'lgvalley@uvm.edu')
... """)
... cnx.commit()Let’s check that all these records are now present.
>>> result = cursor.execute("SELECT * FROM member")
>>> for row in result.fetchall()
... print(row)
...
Row(club_name='Agriculture Club', given_name='Hortense',
surname='Greenthumb', email='hgreenthumb@uvm.edu')
Row(club_name='Agriculture Club', given_name='Travis',
surname='Wilbury', email='tqwilbury@uvm.edu')
Row(club_name='Agriculture Club', given_name='Richard',
surname='Mason', email='rymason21@uvm.edu')
Row(club_name='Agriculture Club', given_name='Flora',
surname='Landis', email='ftlandis@uvm.edu')
Row(club_name='Agriculture Club', given_name='Lillian',
surname='Valley', email='lgvalley@uvm.edu')This looks OK, but notice that the president of the Agriculture Club appears in both tables. That’s redundant and brittle. What should be done?
We could use some unique identifier (for example, email address) for the president of the club in the club table, or we could add a field to the member table to use as an indicator that a particular member is the president. Let’s go with the second option.
To implement this, we need to alter both tables. We’re going to remove the president column from the club table, and we’re going to add a new column to the member table to hold the indicator of presidency.
For the first, we’ll use ALTER TABLE and DROP COLUMN (drop means “delete”).
>>> cursor.execute("""
... ALTER TABLE club
... DROP COLUMN president
... """)
...
>>> cnx.commit()
>>> result = cursor.execute("SELECT * FROM club")
>>> for row in result.fetchall():
... print(row)
...
Row(name='African Student Association', year=2020)
Row(name='Agriculture Club', year=2019)
Row(name='Alianza de Latines', year=2021)
Row(name='American Sign Language Club', year=2017)
Row(name='Anthropology Club', year=2022)
Row(name='Archery Club', year=2023)
Row(name='Art Club', year=2020)
Row(name='Asian Student Union', year=2021)Where did the president data go? It’s gone forever! Accordingly, you should proceed with caution when dropping columns—this is a destructive operation.
Notice something else about this result. We’re still using named tuples here, and despite having changed the table schema, our row factory method is working just fine. That’s because we designed it to dynamically construct a (local) namedtuple class directly from query results. Neat!
Now let’s use ALTER TABLE with ADD COLUMN to modify the member table. But first, let’s ask, what datatype should we use for this column? Remember, the goal is to have an indicator as to which member of a given club is its president. You might think a Boolean would be appropriate, but SQLite doesn’t have a Boolean datatype (other dialects of SQL do). So we could use a letter, e.g., 'Y', 'N', or we could use an integer, 1 or 0. Since the latter is closer in spirit to a Boolean let’s go with that. However, we might want to constrain the values to 1 or 0 to prevent inserting a record with 5 (what on earth could that mean?). To emulate a Boolean we’ll use SQLite’s CHECK to add a column constraint. We’ll also specify that this column should not be null and that it should have a default value of 0.
>>> cursor.execute("""
... ALTER TABLE member
... ADD COLUMN president
... INTEGER NOT NULL DEFAULT 0
... CHECK(president IN (0,1))
... """)
...
>>> cnx.commit()Now let’s check to see what a record looks like.
>>> cursor.execute("""
... SELECT *
... FROM member
... WHERE club_name = 'Agriculture Club'
... """)
...
>>> result.fetchone()
Row(club_name='Agriculture Club', given_name='Hortense',
surname='Greenthumb', email='hgreenthumb@uvm.edu',
president=0)This looks OK, and notice that again, our dynamic named tuple factory handles the change automatically.
However, now we need to update Hortense Greenthumb’s record to indicate she’s the club president. For this we’ll use an UPDATE query. For this kind of query, we need to specify the table we wish to update, the columns we wish to update with their new value(s), and the criteria used to select rows we wish to update. We want to update Hortense’s record, setting president = 1, and leave other records unchanged.
>>> cursor.execute("""
... UPDATE member
... SET president = 1
... WHERE email = 'hgreenthumb@uvm.edu'
... """)
>>> cnx.commit()
>>> result.fetchone()
Row(club_name='Agriculture Club', given_name='Hortense',
surname='Greenthumb', email='hgreenthumb@uvm.edu',
president=1)This looks good.
You may notice we used Hortense’s email to identify her record. You may also realize that email address could serve as a unique identifier for a person. We could have two people named Tim Smith at the university, but they’d each have their own email address. Why don’t we set email address to be a unique key field in the member table? Because a person might be a member of more than one club! (We’ll revisit this a little later.)
Let’s add the other presidents for now, to restore information we deleted when dropping a column from the club table. Let’s see a little different approach, assuming we have all the necessary tuples ready to insert:
>>> members = [
... ('African Student Association', 'Amy', 'Adeoye',
... 'aaadeoye@uvm.edu', 1),
... ('Alianza de Latines', 'Ernesto', 'Ortiz',
... 'eeortiz@uvm.edu', 1),
... ('American Sign Language Club', 'Marie', 'Austyn',
... 'mmaustyn@uvm.edu', 1),
... ('Anthropology Club', 'Ken', 'Korey',
... 'kakorey@uvm.edu', 1),
... ('Archery Club', 'Bill', 'Tell',
... 'wmqtell@uvm.edu', 1),
... ('Art Club', 'Julia', 'Fish',
... 'jafish@uvm.edu', 1),
... ('Asian Student Union', 'Michiko', 'Itatani',
... 'michiko.itatani@uvm.edu', 1)
... ]
>>> cursor.executemany("""
... INSERT INTO member (club_name, given_name,
... surname, email, president)
... VALUES (?, ?, ?, ?, ?)
... """, members)
... cnx.commit()This is a convenient way to insert multiple records. The question marks following VALUES are placeholders (called bindings) that are filled in by unpacking the values in each tuple. Notice that this uses cursor.executemany() and that we supply two arguments: the query with the appropriate number of bindings, and the data (here members).
Querying multiple tables with JOIN
Let’s say we wanted to produce a report about clubs on campus. Something that looks like this:
| Club | By-law year | Members | President |
|---|---|---|---|
| Agriculture Club | 2019 | 5 | Hortense Greenthumb |
| … | … | … | … |
We have the by-law year in the club table, and the membership information is in the member table. So for something like this, we’d need to use a join. Joins are a way of connecting tables, so we can extract information in interesting and useful ways.
For this report, we’ll need a join and a calculated column. The number of members in a club isn’t explicitly stored in the database, but we can calculate this in a query.
Let’s start by excluding the name of the president, then we’ll add that later.
To retrieve the club name, by-law year, and count of members, we use JOIN to connect the two tables, COUNT to count rows in the member table, and GROUP BY to tell SQLite how to aggregate the count data.
>>> result = cursor.execute("""
... SELECT club.name,
... club.year,
... COUNT(member.email) AS member_count
... FROM club
... JOIN member
... ON club.name = member.club_name
... GROUP BY club.name
... """)
...
>>> for row in result.fetchall():
... print(row)
...
Row(name='African Student Association', year=2020, member_count=1)
Row(name='Agriculture Club', year=2019, member_count=5)
Row(name='Alianza de Latines', year=2021, member_count=1)
Row(name='American Sign Language Club', year=2017, member_count=1)
Row(name='Anthropology Club', year=2022, member_count=1)
Row(name='Archery Club', year=2023, member_count=1)
Row(name='Art Club', year=2020, member_count=1)
Row(name='Asian Student Union', year=2021, member_count=1)Of course, we haven’t fully populated our database so the member count for every club other than the Agriculture Club is one. Nevertheless, you can see we’ve retrieved the club name, by-law year, and the count of members by club. Let’s unpack that query, because there’s a lot there.
First, notice that in our SELECT statement, we’re specifying the columns we wish to retrieve from the club table. Then we’re using COUNT to get the count of unique email addresses in the member table. There’s no corresponding column for this, and every column in the result must have a name, so we give this the name member_count using AS. But how do we connect these two tables, and how does SQLite know how to aggregate the member count by club? That’s where JOIN ON and GROUP BY come in.
JOIN member
ON club.name = member.club_name club has a column, name, which holds the unique name for each club. Every member record has column club_name which indicates in which club a person is a member. JOIN member ON club.name = member.club_name tells SQLite to use common values in club.name and member.club_name to join the tables. For this to work, the club names in each table have to agree (but we’ve set it up that way). The last bit
GROUP BY club.nametells SQLite how we want to aggregate records for purposes of counting—that we want to aggregate by club name rather than by some other column (we could aggregate by by-law year, for example, but that’s not what we want).
Now let’s see how to add the club president to the report.
>>> result = cursor.execute("""
... SELECT club.name,
... club.year,
... COUNT(member.email) AS member_count,
... p.given_name || ' ' || p.surname AS president
... FROM club
... JOIN member
... ON club.name = member.club_name
... JOIN member
... AS p
... ON club.name = p.club_name
... AND p.president = 1
... GROUP BY club.name
... ORDER BY club.name ASC
... """)
... Here we’re joining twice: once to get the count of members, and once to get the president’s name. Notice that the second join is conditioned on equivalence of club name and the correct value (1) for the president indicator. Like Python, SQLite has AND and OR Boolean connectives.
The last clause
ORDER BY club.name ASC sorts the resulting rows alphabetically by club name. ASC here means in ascending order.
The strange looking bit is this:
p.given_name || ' ' || p.surname AS president The || is SQLite’s string concatenation operator, and it works just like Python’s + would if both operands were strings. So this bit constructs the president’s full name by concatenating their given name with their surname (with a space in-between).
Then, if we wanted to pretty-print a table we could do it like this:
print(f"{'Club':<28} {'Year':>5} "
f"{'Members':>8} {'President':<20}")
print(f"{'-' * 28:<28} {'-' * 5:>5} "
f"{'-' * 8:>8} {'-' * 20:<20}")
for row in result.fetchall():
print(f"{row.name:<28} {row.year:>5} "
f"{row.member_count:>8} {row.president:<20}")and we’d get a nice table like this:
Club Year Members President
---------------------------- ----- -------- --------------------
African Student Association 2020 1 Amy Adeoye
Agriculture Club 2019 5 Hortense Greenthumb
Alianza de Latines 2021 1 Ernesto Ortiz
American Sign Language Club 2017 1 Marie Austyn
Anthropology Club 2022 1 Ken Korey
Archery Club 2023 1 Bill Tell
Art Club 2020 1 Julia Fish
Asian Student Union 2021 1 Michiko Itatani There’s something important to notice in all this. The named tuple factory method continues to work (without alteration!) for this query as well as the queries made against a single table. But wait, you say: the named tuple factory gets column names from a table, but there is no table with these particular columns in this particular order. Well, actually there is a table. The SQLite database engine constructs this table in memory based on the query, so there is indeed a table here, just not one that persists (is saved to disk). All query results are a table.
There’s still a little more we could do to tighten things up a bit.
Consider this: We have a unique key in our club table. This prevents us from creating a duplicate record for a given club. The name of the club must be unique and that’s enforced by SQLite. However, there is no such key in the members table, and this would allow us to create two records for the same student if they were a member in more than one club. This is wasteful and error-prone. But what would be a good unique key for a student? As mentioned earlier, while two students could have the same name, two students cannot have the same email address. However, if we were to make email address a unique key in the member table, this would preclude our being able to have one student be a member of more than one club. What should we do?
We’ll take a common approach. We’ll alter the member table, to become a general-purpose student table with a unique key—email address. If we do this, we’ll need a new way to represent membership—one which allows us to have a single student be in more than one club. The way we’ll accomplish this is with an association table. When we’re done, we’ll have the club table (unchanged), a student table made by altering the member table, and an association table, membership, which links the two. This is a very common pattern in database design.
Let’s create the membership table first. We can do this without a whole lot of work, because we can construct the data we need from the current tables. First, we’ll create the table:
>>> cursor.execute("""
... CREATE TABLE membership (
... club_name TEXT NOT NULL,
... email TEXT NOT NULL,
... joined INTEGER,
... president INTEGER NOT NULL DEFAULT 0
... CHECK(president IN (0,1))
... );
... """)
>>> cnx.commit()Now, let’s populate this with the appropriate data. We already have all the data in question, so we’ll write one query to fetch what we need to populate this table, and then another to insert the data into the new table.
>>> result = cursor.execute("""
... SELECT club_name, email, null AS joined, president
... FROM member
... """)
...
>>> data = result.fetchall()
>>> for row in data:
... print(row)
...This is what we get.
Row(club_name='Agriculture Club',
email='hgreenthumb@uvm.edu',
joined=None, president=1)
Row(club_name='Agriculture Club',
email='tqwilbury@uvm.edu',
joined=None, president=0)
Row(club_name='Agriculture Club',
email='rymason21@uvm.edu',
joined=None, president=0)
Row(club_name='Agriculture Club',
email='ftlandis@uvm.edu',
joined=None, president=0)
Row(club_name='Agriculture Club',
email='lgvalley@uvm.edu',
joined=None, president=0)…and so on.
Notice that we’ve saved this result, assigning it to the variable name data. We’re going to use this in our insert query.
>>> cursor.executemany("""
... INSERT INTO membership (club_name, email,
... joined, president)
... VALUES (?, ?, ?, ?)
... """, data)
...
>>> cnx.commit()That’s it! Now our membership table is populated! (We could have written this as a single query, but I think it’s easier to read if we break it into two queries.)
Now that we’ve constructed our membership table, we can alter the member table without losing any data.
>>> cursor.execute("ALTER TABLE member RENAME TO student")
>>> cnx.commit()
>>> cursor.execute("ALTER TABLE student DROP COLUMN club_name")
>>> cnx.commit()
>>> cursor.execute("ALTER TABLE student DROP COLUMN president")
>>> cnx.commit() That completes our schema migration. Notice that club no longer stores email addresses, and that student (formerly member) no longer stores club information. This is good separation of concerns in database design.
All that’s left is to rewrite the report query.
>>> result = cursor.execute("""
... SELECT club.name,
... club.year,
... COUNT(student.email) AS member_count,
... s.given_name || ' ' || s.surname AS president
... FROM club
... JOIN membership
... ON club.name = membership.club_name
... JOIN student
... ON membership.email = student.email
... JOIN membership AS mm
... ON club.name = mm.club_name AND mm.president = 1
... JOIN student AS s
... ON mm.email = s.email
... GROUP BY club.name
... ORDER BY club.name ASC
""")If we issue this query and print out the result as before we get the same result.
Club Year Members President
---------------------------- ----- -------- ------------------------
African Student Association 2020 1 Amy Adeoye
Agriculture Club 2019 5 Hortense Greenthumb
Alianza de Latines 2021 1 Ernesto Ortiz
American Sign Language Club 2017 1 Marie Austyn
Anthropology Club 2022 1 Ken Korey
Archery Club 2023 1 Bill Tell
Art Club 2020 2 Julia Fish
Asian Student Union 2021 1 Michiko Itatani Because we’ve nicely separated concerns, we have no duplication of data if we have a student or students who are members of more than one club. We can also add columns to club that are specific to clubs, e.g, website URLs, meeting pattern, etc., and columns that are specific to students to the student table, e.g., class (graduation year), home address, etc. We could also add queries to get a roster of members for a given club, or to display all the clubs of which a given student is a member. These are left as exercises for the reader.
A quick look at dataclass
Python’s dataclass is widely used with databases, and it sits quite comfortably between named tuples and full-fledged OOP in complexity. Python makes it easy to define classes for your data without a whole lot of coding overhead (called “boilerplate”).
Let’s make a dataclass for student data.
>>> from dataclasses import dataclass
>>> @dataclass # tell Python this is a dataclass definition
... class Student:
... given_name: str
... surname: str
... email: str That’s a minimal example, and this would work with rows returned from our student table. Let’s expand on this just a little so that we can get a feel for things we can do with such classes.
>>> from dataclasses import dataclass
>>> @dataclass # tell Python this is a dataclass definition
... class Student:
... given_name: str
... surname: str
... email: str
... @property
... def full_name(self):
... return f"{self.given_name} {self.surname}"
... @property
... def contact(self):
... return f"{self.full_name} <{self.email}>"@property is a decorator which turns a method into a property field. In doing so, we make each property full_name and contact accessible without having to provide an empty parenthesised parameter list. So if we have an object of this type student we can access the student’s full name (given name and surname) with student.full_name rather than the awkward student.full_name().
Let’s take it out for a test drive.
>>> result = cursor.execute("""
... SELECT * FROM student
... ORDER BY surname ASC")
>>> students = []
>>> for student in result.fetchall():
... s = Student(*student)
... print(s.contact)
... students.append(s)
...
Amy Adeoye <aaadeoye@uvm.edu>
Marie Austyn <mmaustyn@uvm.edu>
Julia Fish <jafish@uvm.edu>
Hortense Greenthumb <hgreenthumb@uvm.edu>
Michiko Itatani <michiko.itatani@uvm.edu>
Ken Korey <kakorey@uvm.edu>
Flora Landis <ftlandis@uvm.edu>
Richard Mason <rymason21@uvm.edu>
Ernesto Ortiz <eeortiz@uvm.edu>
Bill Tell <wmqtell@uvm.edu>
Roxie Tremonto <rrtremonto@uvm.edu>
Lillian Valley <lgvalley@uvm.edu>
Travis Wilbury <tqwilbury@uvm.edu> How cool is that? Notice also that we saved the objects created from retrieved records in a list called students for future use. We did it this way because we did not use this datatype-based class in the row factory—we constructed the objects after the query was returned.
This only hints at the full capabilities of dataclasses.
We won’t get into it here, but you should be aware that SQLite has some support for JSON. This comes in handy, for example, when you have an application that exchanges data with a web API (application program interface).
By no means is this a complete introduction to SQLite with Python, but it should serve to get you started. We’ve covered:
- database connections and cursors,
- table creation,
- altering tables,
- inserting data,
- queries on single tables,
- queries on joined tables,
- row factory methods, including
sqlite3.Row, and- named tuples,
dataclassobjects and properties, and- association tables.