Obtaining a FASTA Formatted Amino Acid Sequence
As a shortcut, we will use the Entrez "Gene" database to quickly access the amino acid sequence of a gene product. The amino acid sequence also could be obtained by searching protein sequence databases such as NCBI's Entrez; this process, however, can be more involved and rather time consuming since it often requires examining and sifting through several sequence records.
To begin, go to the Entrez Gene site at NCBI:
Click on the image to see full-size! |
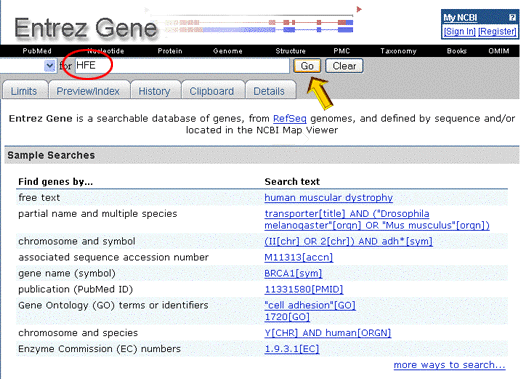
Enter
the gene symbol (HFE) in the search box at the top of the Entrez Gene page, then
click on "GO".
Records will be retrieved for the hemochromatosis gene in humans as well as mouse (Mus musculus), Norway rat (Rattus norvegicus), cow (Bos taurus), etc. NOTE: The field qualifier [sym] can be used to limit the search by gene symbol only. Since a gene symbol is unique for each human gene, you should retrieve only one result. For more information on options for refining your search, follow the link in the sidebar to the "Gene Handbook".
Click on the link for the human HFE protein. |
|
|
|
k on the image to see full-size! |
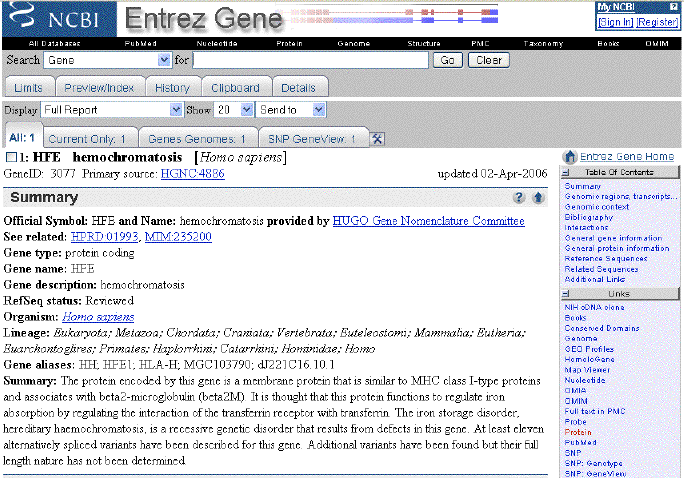
The Summary section. This
section provides basic information about the gene, such as its symbol,
alternative symbols (aliases), species, lineage, etc.
Perhaps the most informative line is the "Summary" which discusses the structure and function of the protein, its role in disease, its inheritance, and the molecular defects which are known. |
|
|
|
Click on the image to see full-size! |
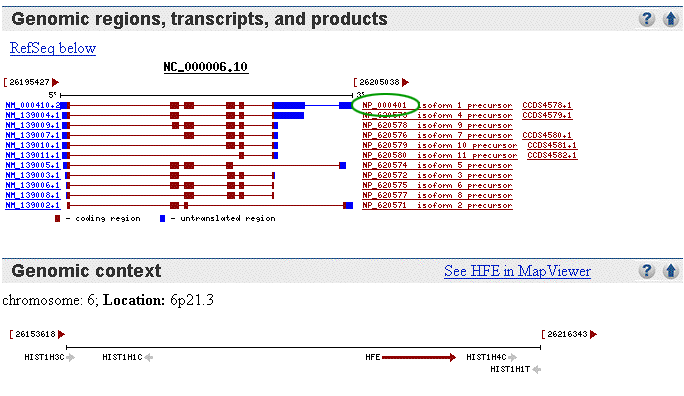
The Genomic region, transcripts
and products section. The graphic in this section depicts 11
different isoforms of the HFE gene. The longest isoform is at the top.
Note that all the remaining isoforms carry deletions in either the 5' UTR,
an exon, or a 3' UTR. For example:
|
The Genomic context section. This section
provides information about the locus of the gene.
The accession number in the Protein database for isoform 1 is NP_000401.1 on the right in the graphic. ( If it does not open scroll to the mRNA and Protein Section to find it) Click on this link to open the record. |
|
|
|
|
Click on the image to see full-size! |
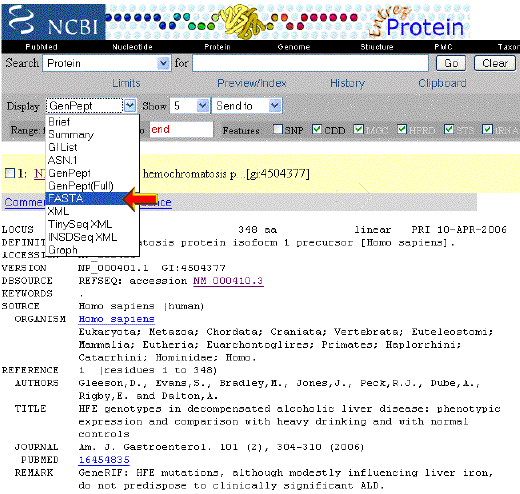
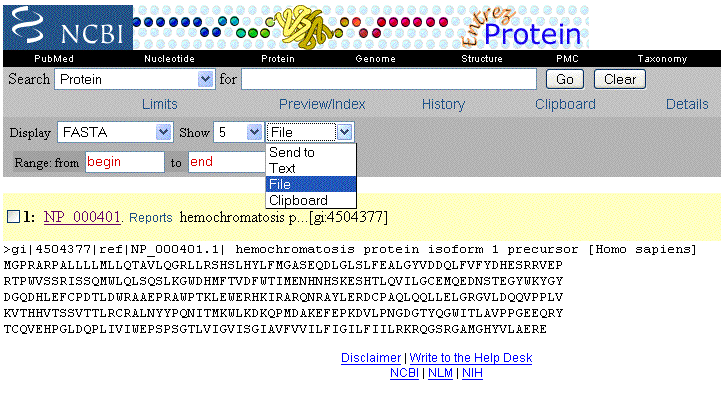
The protein database contains sequence
data from the translated coding regions from DNA sequences in GenBank,
EMBL and DDBJ, as well as protein sequences submitted to Protein Information
Resource (PIR), SWISS-PROT, Protein Research Foundation (PRF), and Protein
Data Bank (PDB).
The flat file format of the Protein database is the same as for nucleotide sequences in GenBank. However the data in each record can also be displayed in numerous other formats, including the FASTA format.
Open the pull-down "Display" menu, and click on "FASTA" |
|
|
|
Click on the image to see full-size! |
A record in FASTA format begins with
a one-line description, followed by the sequence.
Open the pull-down “Send To” menu and click on “File”. Using the dialog box which appears, save the sequence in FASTA format to your desktop. |
|
Back to "Sequence similarity searching using NCBI BLAST" Back to "Index for ENTREZ and Data Base Searches" RETURN TO SITE MAP |