
This page was designed to go with an entry that I wrote for the International Encyclopedia of Statistical Sciences, Lovric (2010). In that paper I discussed four different designs under which one could derive a contingency table, and pointed out that there were randomization tests that could replace Pearson's chi-square for at least three of them. (I haven't figured out a sampling scheme for the fourth.) The main purpose of this page is to illustrate more about the design and meaning of such studies and to present those randomization tests as functions (or programs) in R, which is a freely available (though very slightly different) version of S-PLUS. R can be download from the R Project at http://www.r-project.org/. A more complete version can be found at Contingency-Tables.pdf
Pearson's chi-square was originally developed by Pearson
in papers published in 1900 and 1904. It has had somewhat of a
controversial past, beginning with the fact that Pearson got the
degrees of freedom wrong and was most unhappy when Fisher pointed
that out. Essentially, Pearson showed that the statistic
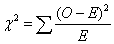
was distributed approximately as the chi-square
distribution. For an r × c table it will be distributed on
(r-1)(c-1) df. And when the sample sizes are reasonably
large with at an expected value of 5 in each cell, the
approximation is quite good. Certainly good enough for our
purposes.
The problem arises when the expected frequency in one or more cells is too small. When that happens, the chi-square statistic can only take on a limited number of different values, and hence its distribution can not be well approximated by the chi-square distribution, which is continuous. For example, when we have a 2 × 2 table with marginal frequencies of 4 in each row and column, there are only 3 possible values of chi-square (0, 2, and 8). Certainly we cannot expect a continuous distribution to be a good fit under such extreme conditions.
In an attempt to adjust for this problem, Yates(1934) proposed a correction that simply involved reducing the absolute value of each numerator by 0.5 before squaring. This correction actually worked reasonably well, but it was still an approximation. Yates' correction has been falling out of favor for many years, but most software still produces it, sometimes without notice. In its place Fisher's Exact Test Fisher (1935), sometimes known as the Fisher-Irwin Test, has taken its place in many situations. This test is not dependent on the chi-square distribution and is, under certain conditions, exact.
| Observed # Cell 11 |
Probability |
| 0 | .014 |
| 1 | .229 |
| 2 | .514 |
| 3 | .229 |
| 4 | .014 |
Ideally, Muriel should have placed 4 cups in cell11 and 4 cups in cell22. The probability that she would do that well by chance in only .014, and we would likely conclude that she had a true ability with respect to tea tasting. But, unfortunately, she had cell totals of 3/1/1/3, which would have a cumulative probability of .013 + .229 = .243, which would not lead to rejection of the null hypothesis. (Fisher's daughter, Joan Fisher Box) reported that Muriel did eventually convince Fisher that she was correct.) In this particular example, and in all of the other examples that my limited imagination can think of, we will only get excited if the judge does very well. We won't particularly care if she gets it all wrong. So what we really have here is a one-tailed test. We sum the probabilities of 4 and 3 correct responses, but we don't also add in the probabilities of 1 and 0 correct responses. In the more general case of a contingency table, we will likely want to use a two-tailed test, but that does not seem to make sense here.
A function already exists for R that will calculate Fisher's exact probability. It is named "fisher.test" and is in the "stats" package, which is part of the base package of R and does not need to be installed separately. The code to compute Fisher's Exact Test as well as the corresponding chi-square test with, and without, Yates' correction can be found the the file named Fisher.R. In this case we are only concerned whether Ms Bristol scored better than chance, so I have specified a one-tailed by adding 'alternative = "greater" .' The chi-square test is always two-sided, so to draw a comparison you would want to divide those probabilities by 2. The results follow the program. The warnings simply refer to the fact that expected values are less than 5.
The data matrix
Col
Row 1 2
1 3 1
2 1 3
Fisher's exact test
Fisher's Exact Test for Count Data
data: Bristol
p-value = 0.2429
alternative hypothesis: true odds ratio is greater than 1
95 percent confidence interval:
0.3135693 Inf
sample estimates:
odds ratio
6.408309
Pearson's (two-sided) chi-square test without Yates' correction
Pearson's Chi-squared test
data: Bristol
X-squared = 2, df = 1, p-value = 0.1573
Pearson's (two-sided) chi-square test with Yates' correction
Pearson's Chi-squared test with Yates' continuity correction
data: Bristol
X-squared = 0.5, df = 1, p-value = 0.4795
Warning messages:
1: In chisq.test(Bristol, correct = FALSE) :
Chi-squared approximation may be incorrect
2: In chisq.test(Bristol, correct = TRUE) :
Chi-squared approximation may be incorrect
As originally conceived, this test applied only to 2 × 2 tables. However the test is not limited by the size of the table (within reasonable limits). See the help file (?fisher.test) for a fuller explanation.The test is not always exact for larger tables, but it is very close.
Fisher's Exact Test is an exact test only if both sets of marginals are fixed. In that case the reference distribution consists of probability values associated with all possible arrangements of data preserving those marginal totals. But what if only the row (or column) marginals are fixed. An example of such a situation is taken from my entry referred to above.
In 2000 the Vermont legislature approved a bill authorizing civil unions. The results of that vote, broken down by the gender of the legislator, is shown below.
|
Vote
|
|||
|
For
|
Against
|
||
|
Women
|
35
|
9
|
44
|
|
Men
|
60
|
41
|
101
|
|
|
95
|
50
|
145
|
This was an important vote, and all legislators were there. So if the vote were to be repeated over and over again, there would always be 44 women and 101 men. In other words the row totals are fixed. The column totals would not be known in advance, so they are random. If we apply the standard Pearson chi-square test to these data we have χ2 = 5.50 on 1 df, with an associated probability of .019.
If we wish to create a randomization test for this design, the appropriate reference distribution would be the probabilities associated with all possible outcomes having those specific row totals. This is no longer the hypergeometric distribution because the column totals are not longer fixed. The R code for such a sampling design can be found at R-CodeContin.html. The first thing that we do is to calculate the obtained chi-square for the data (here, 5.50) To create the random samples, we first calculate the marginal column probabilities. For this example they are .655 and .345. We then draw 44 cases for the first row and assign cases to cell11 with probability = .655. To do this we draw 44 uniformly distributed random numbers between 0 and 1. If a number is less than 0.655, that case is assigned to the "For" category. Otherwise it is assigned to the "Against" category. This process is repeated for 101 cases in row 2. We then calculate a chi-square statistic, though several other measures are possible, such as the frequency of cell11, but chi-square is a good choice because it does not depend on the dimensionality of the table. This process is repeated a large number of times (here 10,000) and the chi-square values for each random table are recorded. Finally, the "exact" probability is computed as the proportion of the 10,000 tables whose χ2 values exceed χ2 for the original data table.
The probability in this case, and in the next, is not "exact" because we generate a random set of tables rather than the full set of all possible tables with those row totals. However, with 10,000 samples the probability will be very close to exact. And because we have large cell frequencies in our example, it should be close to the probability given by Pearson's chi-square. The code also produces a likelihood ratio chi-square and its probability.
Suppose that instead of asking the Vermont Legislators to take a vote, we went out and drew a random sample of 145 Vermont residents and asked their opinion. In this case neither the row nor the column marginals would be fixed because we do not know in advance how many men and women will be in our sample, nor how many will vote "for and "against civil unions. This type of design is quite common.
The appropriate reference distribution of random tables is different in this case. What I did was to compute the proportions in each row and the proportions in each column. If Vote is independent of Gender, the probability of an observation falling in each cell is the product of its row and column proportions. I then sampled N uniformly distributed random numbers between 0 and 1, and made cell assignments based on cell probabilities. For example, if in a 2 × 3 table 40% of observations fell in row 1 and 30% of observations fell in column 3, then I would expect 40% × 30% = 12% to fall in cell13 if rows and columns are independent. Assume that the corresponding percentages in row 1 were 20% and 5% for cell11 and cell12 Then a random number between 0 and .20 would be assigned to cell11, a number between .20001 and .25 would be assigned to cell12, a number between .2500001 and .37 would be assigned to cell13, and so on. The cell frequencies that result would be a random sample of cell frequencies having a total sample size of N. The rest of the process is the same as above. Out of 10,000 tables, and their associated chi-squares, the probability under the null would be the proportion of them that equaled or exceeded the chi-square for the obtained data. The R code to carry out this analysis is presented in the third part of R-CodeContingency.html.
The logical next step would be to consider a study where we went into classrooms and asked students to vote. In this case we not only do not know how many men and women there will be, nor the number of For and Against votes, but we don't even know the total sample size.
It may be possible to generate random samples with this design, but I have not figured out how to do it. I would first have to draw a random sample size, then repeated the calculations in the previous section, then draw another random sample size, and so on. I seriously doubt that it is worth the computational time needed to carry out this process. I suppose that it could be done, but I'm not going to do it.
In many situations the above procedures might be considered overkill. When we have large expected frequencies in all of the cells, the Pearson chi-square test is quite appropriate. The difference in probability values between that statistic and the ones given here will be small. However when we have one or more small expected frequencies things start to fall apart. Campbell (2007) in an extensive study of 2 × 2 tables, concluded that Fisher's Exact Test works well enough when we have small expected frequencies. He also concluded that a modified Pearson's chi-square (χ2×(N/(N-1) is satisfactory when the smallest expected frequency is greater than 1 for 2 × 2 tables. However there is no reason why we need to be satisfied with "well enough" when we have a more appropriate solution.
Campbell, I. (2007). Chi-squared and fisher-Irwin tests of two-by-two tables with small sample recommendations. Statistical in Medicine, 26, 3661-3675. The Design of
ExperimentsEdinburgh, Oliver and Boyd. Return
Fisher, R. A. (1935). The Design of
ExperimentsEdinburgh, Oliver and Boyd. Return
Howell, D. C. ,(2010). Chi-square test: Analysis of contingency tables.
In Lovric, M. (2011). International Encyclopedia of Statistical Science, Springer-Verlag, Berlin. Return
Yates, F. (1934). Contingency tables
involving small numbers and the χ2 test.
Journal of the Royal Statistical Society Supplement
1:217-235. Return
 Return to
Dave Howell's Statistical Home Page
Return to
Dave Howell's Statistical Home Page
Last revised 10/2/2009
