| 2 X 5 factorial design |
A factorial design with one variable having two levels
and the other having five levels. |
| |
|
| Alpha (a) |
The probability of a Type I error. |
| |
|
| Abscissa |
Horizontal axis. |
| |
|
| Additive law of probability |
The rule giving the probability of the occurrence of
one or more mutually exclusive events. |
| |
|
| Adjacent values |
Actual data points that are no more extreme than the
inner fences. |
| |
|
| Adjusted correlation
(radj) |
A correction to the computed correlation coefficient to
adjust for the number of predictors relative to the sample
size. |
| |
|
| Adjusted means |
Means that have been adjusted for differences on a
covariate. |
| |
|
| All subsets regression |
The result of a stepwise multiple regression when the
program chooses that set of variables that has the best
correlation with the critierion. |
| |
|
| Alternative hypothesis
(H1) |
The hypothesis that is adopted when H0 is
rejected. Usually the same as the research hypothesis. |
| |
|
| Analysis of variance (ANOVA) |
A statistical technique for testing for differences in
the means of several groups. |
| |
|
| Analysis of covariance |
An analysis of variance in which the data are adjusted
(or controlled) for the presence of one or more other
variables. |
| |
|
| Analytic view |
Definition of probability in terms of analysis of
possible outcomes. |
| |
|
| Array |
The set of Y values associated with a given
X, or the set of X values associated with a
given Y. |
| |
|
| Asymmetric relationships |
Log-linear models where at least one variable is
treated as an independent variable and at least one
variable is treated as a dependent variable. |
| |
|
| Backward elimination |
A stepwise regression procedure in which we start with
all predictors and them eliminate those that do not
contribute significantly or up to some predetermined
standard. |
| |
|
| Behrens-Fisher problem |
An old name given to the problem of how to compare two
independent means when we can not assume homogeneity of
variance. |
| |
|
| Bernoulli trial |
A outcome with one of two mutually exclusive
outcomes--such as pass/fail. |
| |
|
| b (Beta) |
The probability of a Type II error. |
| |
|
| Betweensubjects designs |
Designs in which different subjects serve under the
different treatment levels. |
| |
|
| Bimodal |
A distribution having two distinct peaks. |
| |
|
| Binomial distribution |
The distribution in which each of a number of
independent trials results in one of two mutually exclusive
outcomes. |
| |
|
| Biserial correlation |
The correlation between a continuous variable and a
dichotomous variable, where we assume an underlying
normality to the dichotomous variable. Rarely used. |
| |
|
| Bivariate normal model |
A regression model in which both X and Y
are subject to random error. |
| |
|
| Bonferroni inequality |
An inequality on which the Bonferrone test is based. It
states that the probability of the occurrence of one or
more events can never exceed the sum of their individual
probabilities. |
| |
|
| Bonferroni test |
A multiple comparison procedure in which the familywise
error rate is divided by the number of comparisons. |
| |
|
| Box-and-whisker plot |
A graphical representation of the dispersion of a
sample. |
| |
|
| Boxplot |
A graphical representation of the dispersion of a
sample. |
| |
|
| Carryover effect |
The effect of previous trials (conditions) on a
subject's performance on subsequent trials. |
| |
|
| Categorical data |
Data representing counts or number of observations in
each category. |
| |
|
| Cell |
The combination of a particular row and column; the set
of observations obtained under identical treatment
conditions. |
| |
|
| Censored data |
Data that have been categorized into two or more groups
on the basis of a cutoff score on some criterion variable.
Often a consideration in logistic regression. |
| |
|
| Centering |
The process of converting data to deviation
scores. |
| |
|
| Central limit theorem |
The theorem that specifies the nature of the sampling
distribution of the mean. |
| |
|
| Chi-square distribution |
The distribution of the chi-square (c2) statistic. |
| |
|
| Chi-square test |
A statistical test often used for analyzing categorical
data. |
| |
|
| Coefficient of variation (CV) |
The standard deviation divided by the mean. |
| |
|
| Collinearity |
The condition in which the independent variables are
(usually highly) correlated with each other. |
| |
|
| Column totals |
The total number of observations occurring in a column
of a contingency table. |
| |
|
| Combinations |
The number of ways objects can be selected without
regard to order. |
| |
|
| Combinatorics |
The branch of mathematics dealing with the number of
different ways objects can be selected or arranged. |
| |
|
| Compound symmetry |
The condition with constant variances on the main
diagonal of a matrix, and constant covariances off the main
diagonal. |
| |
|
| Concordant pairs |
A pair of observations that are ordered in the same
direction on two variables. |
| |
|
| Conditional distribution |
The distribution of Y for a fixed level of
X. |
| |
|
| Conditional means |
The means for one variable at individual levels of a
second variable. |
| |
|
| Conditional odds |
The odds of success given some level of another
variable. |
| |
|
| Conditional probability |
The probability of one event given the
occurrence of some other event. |
| |
|
| Confidence interval |
An interval, with limits at either end, with a
specified probability of including the parameter being
estimated. |
| |
|
| Confidence limits |
An interval, with limits at either end, with a
specified probability of including the parameter being
estimated. |
| |
|
| Confounded |
Two variables are said to be confounded when they are
varied simultaneously and their effects cannot be
separated. |
| |
|
| Constant |
A number that does not change in value in a given
situation. |
| |
|
| Contingency table |
A twodimensional table in which each observation
is classified on the basis of two variables
simultaneously. |
| |
|
| Contingency coefficient |
A coefficient, based on chi-square, reflecting the
degree of relationship exhibited in a contingency
table. |
| |
|
| Continuous variables |
Variables that take on any value. |
| |
|
| Contrast |
A comparison between two levels (or two sets of levels)
of the independent variable following an analysis of
variance. |
| |
|
| Cook's D |
A measure of the influence of an observation in
multiple regression. |
| |
|
| Correlation (r) |
Relationship between variables. |
| |
|
| Correlation coefficient |
A measure of the relationship between variables. |
| |
|
| Correlational measures |
A measure of the degree of relationship between two
variables that are each at least ordinal. |
| |
|
| Count data |
Data representing counts or number of observations in
each category. |
| |
|
| Counterbalancing |
An arrangement of treatment conditions designed to
balance out practice effects. |
| |
|
| Covariance (sxy or
covxy) |
A statistic representing the degree to which two
variables vary together. |
| |
|
| Covariance matrix (S) |
A matrix of variances and covariances among
variables. |
| |
|
| Covariate |
A variable whose influence is controlled in the
analysis of covariance. |
| |
|
| Cramér's phi (Fc) |
The extension of the phi coefficient to the case of
larger contingency tables. |
| |
|
| Criterion variable |
The variable to be predicted. |
| |
|
| Critical value |
The value of a test statistic at or beyond which we
will reject H0 . |
| |
|
| Cross- correlation |
The correlation between one predictor and all other
predictors. |
| |
|
| Cross- validation |
The result of taking a regression equation from one set
of data, applying it to a new set of data, and examining
the correlation between the predicted and obtained values
on the new set of data. |
| |
|
| Curvilinear relationship |
A situation that is best represented by something other
than a straight line. |
| |
|
| Deciles |
Points that divide the distribution into tenths. |
| |
|
| Decision tree |
Graphical representation of decisions involved in the
choice of statistical procedures. |
| |
|
| Decision making |
A procedure for making logical decisions on the basis
of sample data. |
| |
|
| Degrees of freedom (df) |
The number of independent pieces of information
remaining after estimating one or more parameters. |
| |
|
| Delta (d) |
A value used in referring to power tables that combines
gamma and the sample size. |
| |
|
| Density |
Height of the curve for a given value of X- closely
related to the probability of an observation in an interval
around X. |
| |
|
| Dependent variables |
The variable being measured. The data or score. |
| |
|
| Depth |
Cumulative frequency counting in from the nearer
end. |
| |
|
| Design matrix |
A matrix of coded or dummy variables representing group
membership. |
| |
|
| dferror |
Degrees of freedom associated with SSerror =
k(n - 1). |
| |
|
| dfgroup |
Degrees of freedom associated with SSgroup =
k - 1. |
| |
|
| dftotal |
Degrees of freedom associated with SStotal =
N - 1. |
| |
|
| Deviation scores |
Data in which the mean has been subtracted from each
observation. |
| |
|
| Descriptive statistics |
Statistics which describe the sample data without
drawing inferences about the larger population. |
| |
|
| Dichotomous variables |
Variables that can take on only two different
values. |
| |
|
| Difference scores |
The set of scores representing the difference between
the subjects' performance on two occasions. Also known as
"gain scores." |
| |
|
| Directional test |
A test that rejects extreme outcomes in only one
specified tail of the distribution. |
| |
|
| Discordant pairs |
A pair of observations that are ordered in opposite
directions on two variables. |
| |
|
| Discriminant analysis |
A procedure for developing a procedure for optimally
discriminating between two groups. This technique often
being replaced with logistic regression. |
| |
|
| Discrete variables |
Variables that take on a small set of possible
values. |
| |
|
| Disordinal interaction |
An interaction in which group differences reverse their
sign at some level of the other variable. |
| |
|
| Dispersion |
The degree to which individual data points are
distributed around the mean. |
| |
|
| Distance |
The vertical distance between a point and the
regression line. Usually known as the "residual." |
| |
|
| Distributionfree tests |
Statistical tests that do not rely on parameter
estimation or precise distributional assumptions. |
| |
|
| Dotplot |
A distribution that represents the frequencies of
individual points by stacking dots about the axis--similar
to a histogram. |
| |
|
| Dunn-Sidák test |
A test similar to the Bonferroni test which is based on
a more precise inequality and has slightly more power. |
| |
|
| Dunnett's test |
A multiple comparison procedure for comparing each mean
against a standard control group mean. |
| |
|
| Effect size (d) |
The difference between two population means divided by
the standard deviation of either population. |
| |
|
| Effective sample size |
The sample size needed in equal-sized groups to achieve
the power when we have groups of unequal sizes. It will
generally be less than the total number of subjects in the
unequal groups. |
| |
|
| Efficiency |
The degree to which repeated values for a statistic
cluster around the parameter. |
| |
|
| Equally weighted means |
An analysis of variance in which cell means all carry
the same weight in determining row and column means,
regardless of the number of subjects in each cell. |
| |
|
| Error rate per comparison (PC) |
The probability of making a Type I error on any
specific comparison when using multiple comparison
procedures. |
| |
|
| Error variance |
The square of the standard error of estimate. |
| |
|
| Errors of prediction |
The differences between Y and Yhat. |
| |
|
| Eta squared (h2) |
A measure of the magnitude of effect. Also known as the
correlation ratio. |
| |
|
| Event |
The outcome of a trial. |
| |
|
| Exhaustive |
A set of events that represents all possible
outcomes. |
| |
|
| Expected value |
The average value calculated for a statistic over an
infinite number of samples. |
| |
|
| Expected frequencies |
The expected value for the number of observations in a
cell if H0 is true. |
| |
|
| Experimental hypothesis |
Another name for the research hypothesis. |
| |
|
| Exploratory data analysis (EDA) |
A set of techniques developed by Tukey for presenting
data in visually meaningful ways. |
| |
|
| External validity |
The ability to generalize the results from this
experiment to a larger population. |
| |
|
| Factorial design |
An experimental design in which every level of each
variable is paired with every level of each other
variable. |
| |
|
| Factors |
Another word for independent variables in the analysis
of variance. |
| |
|
| Familywise error rate |
The probability that a family of comparisons contains
at least one Type I error. |
| |
|
| Fisher's Least Significant Difference Test
(LSD) |
A multiple comparison technique that requires a
significant overall F, and that involves standard
t tests between pairs of means. Also known as the
"protected t test." |
| |
|
| First order interaction |
The interaction of two variables. Also known as a
"simple interaction." |
| |
|
| Fixed marginal totals |
The situation in which the marginal totals in a
contingency table are known before the data are collected
and are not subject to sampling error. |
| |
|
| Fixed model Anova |
An analysis of variance model in which the levels of
the independent variable are treated as fixed. |
| |
|
| Fixed variable |
A variable that takes on a specific set of values. An
independent variable who levels are assigned by the
experimenter. |
| |
|
| Fractiles |
A generic name for statistics such as deciles,
percentiles, and quartiles. |
| |
|
| Frequency distribution |
A distribution in which the values of the dependent
variable are tabled or plotted against their frequency of
occurrence. |
| |
|
| Frequency data |
Data representing counts or number of observations in
each category. |
| |
|
| Friedman's rank test for k correlated
samples |
A nonparametric test analogous to a standard one-way
repeatedmeasures analysis of variance. |
| |
|
| Gamma |
The symbol for the effect size. |
| |
|
| Gamma function (G) |
A statistical function closely related to
factorials. |
| |
|
| General linear model |
The basic model underlying the analysis of variance and
multiple regression. |
| |
|
| Geomteric mean |
A mean of n objects that is computed by taking
the nth root of the product of the
n terms. |
| |
|
| Goodnessoffit test |
A test for comparing observed frequencies with
theoretically predicted frequencies. |
| |
|
| Grand total (SX) |
The sum of all of the observations. |
| |
|
| H-spread |
The range between the two hinges. |
| |
|
| Harmonic mean |
The number of elements to be averaged divided by the
sum of the reciprocals of the elements. |
| |
|
| Heavy tailed distribution |
A distribution with a higher percentage of scores in
the tails than we would expect in a normal
distribution. |
| |
|
| Heterogeneity of variance |
A situation in which samples are drawn from populations
having different variances. |
| |
|
| Heterogeneous subsamples |
Data in which the sample of observations could be
subdivided into two distinct sets on the basis of some
other variable. |
| |
|
| Hierarchical log-linear model |
A model in which the presence of an interaction
requires the inclusion of any main effects that comprise
that interaction. |
| |
|
| Hierarchical (sequential) sums of squares |
Sums of squares in the analysis of variance where later
terms in the model are adjusted only for terms that precede
them. |
| |
|
| higher order interaction |
The interaction of three or more variables. |
| |
|
| Hinge location |
The location of the hinge in an ordered series. |
| |
|
| Hinges (Quartiles) |
Those points that cut off the bottom and top quarter of
a distribution. |
| |
|
| Histogram |
Graph in which rectangles are used to represent
frequencies of observations within each interval. |
| |
|
| Homogeneity of regression |
The assumption that the regression line expressing the
dependent variable as a function of a covariate is constant
across several groups or conditions. |
| |
|
| Homogeneity of variance |
The situation in which two or more populations have
equal variances. |
| |
|
| Homogeneity of variance in arrays |
The requirement that the variance in Y
associated with one value of X is the same as the
variance in Y associated with other values of
X. |
| |
|
| Hyperspace |
Multidimensional space beyond the three dimensions that
we can easily represent. |
| |
|
| Hypothesis testing |
A process by which decisions are made concerning the
values of parameters. |
| |
|
| Independent variables |
Those variables controlled by the experimenter. |
| |
|
| Independent events |
Events are independent when the occurrence of one has
no effect on the probability of the occurrence of the
other. |
| |
|
| Inferential statistics |
That branch of statistics that involves drawing
inferences about parameters of the population(s) from which
you have sampled. |
| |
|
| Influence |
A measure of the degree to which an individual data
point can influence the obtained value of a regression
coefficient. |
| |
|
| Inner fences |
Points that are 1.5 times the H-spread above and below
the appropriate hinge. |
| |
|
| Interaction |
A situation in a factorial design in which the effects
of one independent variable depend upon the level of
another independent variable. |
| |
|
| Intercept |
The value of Y when X is 0. |
| |
|
| Intercorrelation matrix |
A matrix (table) showing the pairwise correlations
between all variables. |
| |
|
| Interquartile range |
The range of the middle 50% of the observations. |
| |
|
| Internal validity |
The degree to which a study if logically sound and free
of confounding variables. |
| |
|
| Interval scale |
Scale on which equal intervals between objects
represent equal differences‹differences are
meaningful. |
| |
|
| Interval estimate |
A range of values estimated to include the
parameter. |
| |
|
| Intraclass correlation |
A measure of the degree of relationship between two
variables. It is usually squared. |
| |
|
| Joint probability |
The probability of the co-occurrence of two or more
events. |
| |
|
| Kappa (k) |
Cohen's measure of agreement based on a contingency
table. |
| |
|
| Kendall's coefficient of concordance
(W) |
A coefficient of agreement among two or more
judges. |
| |
|
| Kendall's tau |
A correlation for ranked data which relies on the
number of inversions of the rank order of one variable when
the other variable is ranked in order. |
| |
|
| KruskalWallis one-way analysis of
variance |
A nonparametric test analogous to a standard one-way
analysis of variance. |
| |
|
| Kurtosis |
A measure of the peakedness of a distribution. |
| |
|
|
Latin square design
|
A design which varies the order of presentation of
stimuli in such a way as to distribute sequence effects
across the design. |
| |
|
| Leading digits (most significant digits) |
Left-most digits of a number. |
| |
|
| Least significant difference test |
A technique in which we run t tests between
pairs of means only if the analysis of variance was
significant. |
| |
|
| Leaves |
Horizontal axis of display containing the trailing
digits. |
| |
|
| Leptokurtic |
A distribution that has relatively more scores in the
center and in the tails. |
| |
|
| Leverage |
The degree to which an observation is unusual with
respect to the predictor variables. Similar to an
outlier. |
| |
|
| Likelihood ratio chi- square |
An alternative procedure for calculating the chi-square
statistic--most commonly used in log-linear models |
| |
|
| Linear combination |
The sum of a weighted set of means. 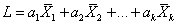 |
| |
|
| Linear contrast |
A linear combination where the sum of the squared
weights sum to 0. |
| |
|
| Linear regression model |
A regression model in which the independent variable
(X) is not subject to random error. |
| |
|
| Linear relationship |
A situation in which the best-fitting regression line
is a straight line. |
| |
|
| Linear transformation |
A transformation involving addition, subtraction,
multiplication, or division of or by a constant. |
| |
|
| Linear regression |
Regression in which the relationship is linear. |
| |
|
| Linearity of regression |
The assumption that the best fitting line for a
bivariate set of data in linear (straight).. |
| |
|
| Log-linear models |
Models for handling multiple categorical variables,
such as a contingency table with three or more
variables. |
| |
|
| Logistic regression |
A variant of standard regression used when the
dependent variable is a dichotomy, such as
success/failure. |
| |
|
| Logit (transform) |
The natural log of the odds of success. |
| |
|
| Magnitude of effect |
A measure of the degree to which variability among
observations can be attributed to treatments. |
| |
|
| Main diagonal |
The diagonal cells of a matrix from upper left to lower
right. |
| |
|
| Main effect |
The effect of one independent variable averaged across
the levels of the other independent variable(s). |
| |
|
| MannWhitney U test |
A nonparametric test for comparing the central tendency
of two independent samples. |
| |
|
| Marginal distribution |
The distribution of Y across all values of
X. In other words, the distribution of Y
ignoring X. |
| |
|
| Marginal totals |
Totals for the levels of one variable summed across the
levels of the other variable. |
| |
|
| Matched samples |
An experimental design in which the same subject is
observed under more than one treatment. |
| |
|
| Matched-samples t test |
A t test comparing the means of matched (or
repeated) samples. |
| |
|
| Matrix algebra |
Algebra in which you work with matrices of elements or
variables instead of individual elements. |
| |
|
| Mean |
The sum of the scores divided by the number of
scores. |
| |
|
| Mean absolute deviation (m.a.d.) |
Mean of the absolute deviations about the mean. |
| |
|
| Measurement |
The assignment of numbers to objects. |
| |
|
| Measurement data |
Data obtained by measuring objects or events. |
| |
|
| Measures of association |
Measures, often based on the chi-square statistic, that
reflect the degree of relationship between two variables.
The variables are often only nominal. |
| |
|
| Measures of central tendency |
Numerical values referring to the center of the
distribution. |
| |
|
| Measures of location |
Another term for measures of central tendency. |
| |
|
| Median (Med) |
The score corresponding to the point having 50% of the
observations below it when observations are arranged in
numerical order. |
| |
|
| Median location |
The location of the median in an ordered series. |
| |
|
| Mesokurtic |
A distribution with a neutral degree of kurtosis. |
| |
|
| Midpoints |
Center of interval -- average of upper and lower
limits. |
| |
|
| Mixed model designs |
Anova designs with one or more between subjects factors
and one or more repeated measures factor. Also refers to
designs with both fixed and random independent
variables. |
| |
|
| Modality |
The term used to refer to the number of major peaks in
a distribution. |
| |
|
| Mode (Mo) |
The most commonly occurring score. |
| |
|
| Monotonic relationship |
A relationship represented by a regression line that is
continually increasing (or decreasing), but perhaps not in
a straight line. |
| |
|
| MSbetween groups
(MSgroup) |
Variability among group means. |
| |
|
| MSwithin (MSerror) |
Variability among subjects in the same treatment
group. |
| |
|
| Multicategory case |
A situation in which data can be sorted into more that
two categories. |
| |
|
| Multicollinearity |
A condition in which a set of predictor variables are
highly correlated among themselves. |
| |
|
| Multinomial distribution |
The distribution in which each of a number of
independent trials results in one of two or more
mutually exclusive outcomes. |
| |
|
| Multiple comparison techniques |
Techniques for making comparisons between two or more
group means subsequent to an analysis of variance. |
| |
|
| Multiple correlation coefficient
(R0.123..p) |
The correlation between one variable (Y) and a set of
p predictors. |
| |
|
| Multiple regression |
Regression with two or more independent variables. |
| |
|
| Multiplicative law of probability |
The rule giving the probability of the joint occurrence
of independent events. |
| |
|
| Multivariate analysis of variance (Manova) |
An analysis of variance with two or more
dependent variables. |
| |
|
| Multivariate outliers |
Observations that are outliers in some multivariate
space. |
| |
|
| Multivariate procedures |
Procedures that deal with two or more dependent
variables simultaneously. |
| |
|
| Multivariate normal distribution |
A generalization of the normal distribution to the
joint distribution of two or more variables. |
| |
|
| Mutually exclusive |
Two events are mutually exclusive when the occurrence
of one precludes the occurrence of the other. |
| |
|
| N factorial (!) |
N*(N-
1)*(N-2)*(N-3)*...*1 |
| |
|
| Negative relationship |
A relationship in which increases in one variable are
associated with decreases in the other. |
| |
|
| Negatively skewed |
A distribution that trails off to the left. |
| |
|
| Newman-Keuls test |
A popular multiple comparison procedure for making
pairwise comparisons among means. |
| |
|
| Nominal scale |
Numbers used only to distinguish among objects. |
| |
|
| Noncentrality parameter |
The degree to which the mean of the sampling
distribution of the test statistic departs from its mean
when the null hypothesis is true. |
| |
|
| Nondirectional test |
A test that rejects extreme outcomes in either tail of
the distribution. |
| |
|
| Non-equivalent groups design |
A design in which the experimental groups differ on one
or more important variables at the start of the
experiment. |
| |
|
| Nonparametric tests |
Statistical tests that do not rely on parameter
estimation or precise distributional assumptions. |
| |
|
| Normal distribution |
A specific distribution having a characteristic
bell-shaped form. |
| |
|
| Normality |
Usually refers to the assumption behind most parametric
tests that the data are normally distributed in the
population. |
| |
|
| Normality in arrays |
The assumption that the Y values in any array of
X are normally distributed. |
| |
|
| Null hypothesis (H0 ) |
The statistical hypothesis tested by the statistical
procedure. Usually a hypothesis of no difference or no
relationship. |
| |
|
| Observed frequencies |
The cell frequencies that were actually observed--as
distinguished from expected frequencies. |
| |
|
| Odds |
The ratio of the probability (p) that an event
occurs to the
probability (1-p) that it does not:
odds=p/(1-p). In a contingency table it is
the ratio of the number of success to the number of
failures. (As distinguished from a probability, which is
the ratio of the number of success to the total number of
events.) |
| |
|
| Odds ratio (W) |
The ratio of two odds. |
| |
|
| Off-diagonal elements |
The elements of a matrix that are not on the main
diagonal. |
| |
|
| Omega squared (w2) |
A less biased measure of the magnitude of effect. |
| |
|
| One-tailed test |
A test that rejects extreme outcomes in only one
specified tail of the distribution. |
| |
|
| One-way ANOVA |
An analysis of variance where the groups are defined on
only one independent variable. |
| |
|
| Order effect |
The effect on performance attributable to the order in
which treatments were administered. |
| |
|
| Ordinal interaction |
An interaction in which the group differences do not
reverse their sign. |
| |
|
| Ordinal scale |
Numbers used only to place objects in order. |
| |
|
| Ordinate |
Vertical axis. |
| |
|
| Orthogonal contrasts |
A set of contrasts that are independent of one
another. |
| |
|
| Outlier |
An extreme point that stands out from the rest of the
distribution. |
| |
|
| p level |
The probability that a particular result would occur by
chance if H0 is true. The exact probability of a
Type I error. |
| |
|
| Parameters |
Numerical values summarizing population data. |
| |
|
| Parametric tests |
Statistical tests that involve assumptions about, or
estimation of, population parameters. |
| |
|
| Partial correlation
(r01.2) |
The correlation between the dependent and independent
variables with the effects of one or more additional
independent variables removed from both sides of the
equation. |
| |
|
| Partialing |
To hold constant the effect of one variable when
looking at the effects of two or more other variables. |
| |
|
| Partition |
To divide up a sum of squares--usually the
SStreatment. |
| |
|
| Pearson product-moment correlation coefficient
(r) |
The most common correlation coefficient. |
| |
|
| Pearson's chi-square (c2) |
The traditional chi-square statistic--as opposed to the
likelihood ratio chi- square. |
| |
|
| Percentage of agreement |
The ratio of the number of times two judges agree,
divided by the number of judgments. It is a measure that
does not correct for chance agreement. |
| |
|
| Percentile |
The point below which a specified percentage of the
observations fall. |
| |
|
| Permutations |
The number of ways objects can be arranged taking
ordering into account. |
| |
|
| Phi (F) |
The correlation coefficient when both of the variables
are measured as dichotomies. |
| |
|
| Platykurtic |
A distribution that is relatively thick in the
"shoulders." |
| |
|
| Point biserial correlation
(rpb) |
The correlation coefficient when one of the variables
is measured as a dichotomy. |
| |
|
| Point estimate |
The specific value taken as the estimate of a
parameter. |
| |
|
| Polynomial trend coefficient |
A set of coefficients used for testing for polynomial
(e.g., linear, quadratic, ...) trend. |
| |
|
| Pooled variance |
A weighted average of the separate sample
variances. |
| |
|
| Population variance |
Variance of the population‹usually estimated,
rarely computed. |
| |
|
| Population |
Complete set of events in which you are
interested. |
| |
|
| Positively skewed |
A distribution that trails off to the right. |
| |
|
| Power |
The probability of correctly rejecting a false
H0 . |
| |
|
| Prediction |
The prediction of one variable (Y) on the basis
of one or more predictor variables
(Xi). |
| |
|
| Predictor variable |
The variable from which a prediction is made. |
| |
|
| Proportional improvement in prediction
(PIP) |
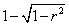 The degree to which the prediction of Y is
improved by using X. The degree to which the prediction of Y is
improved by using X. |
| |
|
| Proportional reduction in error (PRE) |
The degree to which the residual error is reduced after
taking X into account, relative to the error without
X. |
| |
|
| Proportionality |
A condition in a factorial analysis of variance where a
certain proportionality exists among sample sizes. |
| |
|
| Protected t |
A technique in which we run t tests between
pairs of means only if the analysis of variance was
significant. Also known as Fisher's LSD test. |
| |
|
| Quadratic function |
A polynomial function of the 2nd order, which has one
point of inflection. An equation of the form 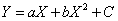 . . |
| |
|
| Quantitative data |
Data obtained by measuring objects or events. |
| |
|
| Qualitative data |
Non-numerical data, often in the form of categorical
data. |
| |
|
| Quantiles |
A generic name for statistics such as deciles,
percentiles, and quartiles. |
| |
|
| Quartiles |
The points which break the distribution into
fourths. |
| |
|
| Random marginal totals |
The situation in which the marginal totals in a
contingency table are not known before the data are
collected and are subject to sampling error. |
| |
|
| Random model Anova |
An analysis of variance model in which the levels of
the independent variable are treated as a random
variable. |
| |
|
| Random sample |
A sample in which each member of the population has an
equal chance of inclusion. |
| |
|
| Random variable |
A random variable is a numerical value which is
determined by the outcomes or events of an experiment.A
random independent variable is one who levels vary from one
replication to another, and are not determined by the
experimenter. |
| |
|
| Randomized blocks design |
A design in which subjects are matched against one
another and put into "blocks" of subjects of the same size
as the number of treatments. Members of each block are then
randomly assigned to treatments. |
| |
|
| Range |
The distance from the lowest to the highest score. |
| |
|
| Range restrictions |
Refers to cases in which the range over which X or Y
varies is artificially limited. |
| |
|
| Ranked data |
Data for which the observations have been replaced by
their numerical ranks from lowest to highest. |
| |
|
| Rankrandomization tests |
A class of nonparametric tests based on the theoretical
distribution of randomly assigned ranks. |
| |
|
| Ratio scale |
A scale with a true zero point -- ratios are
meaningful. |
| |
|
| Real lower limit |
The points halfway between the top of one interval and
the bottom of the next. |
| |
|
| Real upper limit |
The points halfway between the top of one interval and
the bottom of the next. |
| |
|
| Rectangular distribution |
A distribution in which all outcomes are equally
likely. Also known as a uniform distribution. |
| |
|
| Reflection |
The process of reversing the direction of scoring such
that high values become low values and low values become
high values. |
| |
|
| Regression surface |
The equivalent of the regression line in
multidimensional space. |
| |
|
| Regression |
The prediction of one variable from knowledge of one or
more other variables. |
| |
|
| Regression equation |
The equation that predicts Y from X. |
| |
|
| Regression coefficients |
The general name given to the slope and the intercept
‹most often refers just to the slope). |
| |
|
| Regression line |
The line of best fit drawn through a scatterplot. |
| |
|
| Regression surface |
The generalization of the regression line, or the
regression plane, to multidimensional space. |
| |
|
| Rejection level |
The probability with which we are willing to reject H0
when it is in fact correct. |
| |
|
| Rejection region |
The set of outcomes of an experiment that will lead to
rejection of H0 . |
| |
|
| Related samples |
An experimental design in which the same subject is
observed under more than one treatment. |
| |
|
| Relative frequency view |
Definition of probability in terms of past
performance. |
| |
|
| Repeatedmeasures designs |
An experimental design in which each subject receives
all levels of at least one independent variable. |
| |
|
| Replicate |
The repeat an experiment. |
| |
|
| Research hypothesis |
The hypothesis that the experiment was designed to
investigate. |
| |
|
| Residual |
The difference between the obtained and predicted
values of Y. |
| |
|
| Residual error |
The error remaining after the predictor variable(s)
has/have been considered. Another term for residual
variance. |
| |
|
| Residual variance |
The square of the standard error of estimate. |
| |
|
| Resistance |
The degree to which an estimator is not influenced by
the presence of outliers.. |
| |
|
| Rho (r) |
Correlation coefficient on the population. Also
occasionally used for Spearman's rank-order
correlation. |
| |
|
| Robust |
A test is robust if it is not seriously disturbed by
the violation of underlying assumptions. |
| |
|
| Row totals |
The total number of observations occurring in a row of
a contingency table. |
| |
|
| Ryan procedure (REGWQ) |
A multiple comparison procedure that holds the
familywise error rate at a while
having greater power than Tukey's test. |
| |
|
| Sample |
Set of actual observations. Subset of the
population. |
| |
|
| Sample statistics |
Statistics calculated from a sample and used primarily
to describe the sample. |
| |
|
| Sample variance (s2) |
Sum of the squared deviations about the mean divided by
N 1. |
| |
|
| Sample with replacement |
Sampling in which the item drawn on trial N is replaced
before the drawing on trial N + 1. |
| Sampling distributions |
The distribution of a statistic over repeated sampling
from a specified population. |
| |
|
| Sampling distribution of differences between
means |
The distribution of the differences between means over
repeated sampling from the same population(s). |
| |
|
| Sampling distribution of the mean |
The distribution of sample means over repeated sampling
from one population. |
| |
|
| Sampling error |
Variability of a statistic from sample to sample due to
chance. |
| |
|
| Sampling fraction |
The fraction of the number of levels actually used in
an experiment to the potential number of levels that could
have been used. In a fixed model the sampling fraction is
1.0, and in a random model it approaches 0.0. |
| |
|
| Satterthwaite solution |
See Welch-Satterthwaite solution |
| |
|
| Saturated model |
A log-linear model having as many parameters as
unknowns. |
| |
|
| Scalar algebra |
The plain old kind of algebra you learned in high
school--as opposed to matrix algebra. |
| |
|
| Scales of measurement |
Characteristics of relations among numbers assigned to
objects. |
| |
|
| Scatter plot |
A figure in which the individual data points are
plotted in two-dimensional space. |
| |
|
| Scatter diagram |
A figure in which the individual data points are
plotted in two-dimensional space. |
| |
|
| Scattergram |
A figure in which the individual data points are
plotted in two-dimensional space. |
| |
|
| Scheffé test |
A relatively conservative multiple comparison
procedure. |
| |
|
| Second order interaction |
The interaction of three variables. |
| |
|
| Semi-partial correlation
(r0(1.2)) |
The correlation between the dependent and the
independent variables with the effect of another variable
or variables removed from just the independent variables.
Also known as the part correlation. |
| |
|
| Sequence effect |
The situation in which the presentation of one level of
the independent variable has an effect on response to
another level of that variable. |
| |
|
| Sigma (S)--capital |
Symbol indicating summation. |
| |
|
| Sigma (s)--lower
case |
Symbol designating the standard deviation of a
population. |
| |
|
| Sign test |
A statistical test which looks at only the sign, not
the magnitude, of the outcomes. (Often used with the set of
difference scores.) |
| |
|
| Significance level |
The probability with which we are willing to reject
H0 when it is in fact correct. |
| |
|
| Simple effect |
The effect of one independent variable at one level of
another independent variable. (Also known as simple main
effects.) |
| |
|
| Simple interaction |
The interaction of two variables at one level of a
third variable. |
| |
|
| Singular matrix |
A matrix that does not have a unique inverse. |
| |
|
| Skewness |
A measure of the degree to which a distribution is
asymmetrical. |
| |
|
| Slope |
The amount of change in Y for a one unit change in
X. |
| |
|
| Spearman's correlation coefficient for ranked data
(rs) |
A correlation coefficient on ranked data. |
| |
|
| Sphericity |
A condition very like compound symmetry that is
required for repeated-measures designs. |
| |
|
| SScells |
The sum of squares assessing differences among cell
totals. |
| |
|
| SSerror |
The sum of the squared residuals. |
| |
|
| SSerror |
The sum of the sums of squares within each group. |
| |
|
| SSgroup |
The sum of squares of group totals divided by the
number of scores per group minus SX2/N.<
/td> |
| |
|
| SSsubjects |
The sum of squares of subject totals. Usually
calculated to remove those effects from the error
term. |
| |
|
| SStotal |
The sum of squares of all of the scores, regardless of
group membership. |
| |
|
| SSwithin subjects |
Variability within the scores from the same
subject. |
| |
|
| SSY |
The sum of the squared deviations. |
| |
|
| Standard deviation |
Square root of the variance. |
| |
|
| Standard error |
The standard deviation of a sampling distribution. |
| |
|
| Standard error of differences between means |
The standard deviation of the sampling distribution of
the differences between means. |
| |
|
| Standard error of estimate |
The average of the squared deviations about the
regression line. |
| |
|
| Standard scores |
Scores with a predetermined mean and standard
deviation. |
| |
|
| Standard normal distribution |
A normal distribution with a mean equal to 0 and
variance equal to 1. Denoted N (0, 1). |
| |
|
| Standardized regression coefficient (b) |
The regression coefficient that results from data that
have been standardized. |
| |
|
| Statistics |
Numerical values summarizing sample data. |
| |
|
| Stem |
Vertical axis of display containing the leading
digits. |
| |
|
| Stem-and-leaf display |
Graphical display presenting original data arranged
into a histogram. |
| |
|
| Stepwise procedures |
A set of rules for deriving a regression equation by
adding or subtracting one variable at a time from the
regression equation. |
| |
|
| Stepwise regression |
See "stepwise regression." |
| |
|
| Stratification |
The partitioning of subjects into subgroups that are
matched on important variables. |
| |
|
| Structural model |
A theoretical model assumed to underlie the data that
expresses the relationship between the dependent variable
and the independent variables. |
| |
|
| Studentized range statistic (q) |
A test statistic for testing the difference between the
largest and smallest means in a set. |
| |
|
| Studentized residual |
A statistic for evaluating the residual for an
observation in multiple regression. |
| |
|
| Student's t distribution |
The sampling distribution of the t
statistic. |
| |
|
| Subjective probability |
Definition of probability in terms of personal
subjective belief in the likelihood of an outcome. |
| |
|
| Success/Failure |
An arbitrary designation of the two possible outcomes
in Bernoulli trials. |
| |
|
| Sufficient statistic |
A statistic that uses all of the information in a
sample. |
| |
|
| Sums of squares |
The sum of the squared deviations around some point
(usually a mean or predicted value). |
| |
|
| Suppressor variable |
A variable whose correlation with the criterion is
opposite in sign from its regression coefficient. |
| |
|
| Symmetric |
Having the same shape on both sides of the center. |
| |
|
| Symmetric relationships |
Log-linear models in which all variables are treated as
dependent variables. |
| |
|
| T scores |
A set of scores with a mean of 50 and a standard
deviation of 10. |
| |
|
| Tabled distribution of chi-square |
The table showing the critical values of chi-square for
various degrees of freedom and levels of a when the null hypothesis is true. |
| |
|
| Test statistics |
The results of a statistical test. |
| |
|
| Tetrachoric correlation |
The correlation between two dichotomous variables when
underlying normality of each variable is assumed. Rarely
used. |
| |
|
| Tolerance |
One minus the squared correlation of a predictor with
all other predictors. |
| |
|
| Trailing digits (least significant digits) |
Right-most digits of a number. |
| |
|
| Treatment effect |
The difference between the mean of one treatment (or
condition) and the grand mean. |
| |
|
| Trimmed statistics |
Statistics calculated on trimmed samples. |
| |
|
| Trimmed samples |
Samples with a percentage of extreme scores
removed. |
| |
|
| Tukey's HSD test |
A multiple comparison procedure for making pairwise
comparisons among means while holding the familywise error
rate at a. |
| |
|
| Two-Tailed test |
A test that rejects extreme outcomes in either tail of
the distribution. |
| |
|
| Twoway factorial design |
An experimental design involving two independent
variables in which every level of one variable is paired
with every level of the other variable. |
| |
|
| Type I error |
The error of rejecting H0 when it is
true. |
| |
|
| Type II error |
The error of not rejecting H0 when it is
false. |
| |
|
| Unbiased estimator |
A statistic whose expected value is equal to the
parameter to be estimated. |
| |
|
| Unconditional probability |
The probability of one event ignoring the
occurrence or nonoccurrence of some other event. |
| |
|
| Unimodal |
A distribution having one distinct peak. |
| |
|
| Uniform distribution |
A distribution in which all possible outcomes have an
equal chance of occurring. Also known as a rectangular
distribution. |
| |
|
| Univariate design |
An experimental design having only one dependent
variable. |
| |
|
| Unweighted means |
Row or column means based on the average of the cell
means in that row or column--without giving greater weight
to cells with more observations. Also known as equally
weighted means. |
| |
|
| Validities |
The correlations of individual predictor variables with
the criterion. |
| |
|
| Validity |
The degree to which a variable measures what it is
intended to measure. |
| |
|
| Variables |
Properties of objects that can take on different
values. |
| |
|
| Variance |
The sum of the squared deviations from the mean,
divided by the degrees of freedom (N- 1). |
| |
|
| Variance inflation factor (VIF) |
The reciprocal of the tolerance--the degree to which
the standard error of bj is incresed
becuase of the degree to which Xj is
correlated with the other predictors. |
| |
|
| Variance Sum Law |
The rule giving the variance of the sum (or difference)
of two or more variables. |
| |
|
| Venn diagrams |
A way of representing shared and unshared variances by
a set of overlapping circles. |
| |
|
| Weighted average |
The mean of the form: (a1X1 +
a2X2)/(a1 + a2)
where a1 and a2 are weighting factors
and X1 and X2 are the values to be
average. |
| |
|
| Weighted means |
Row or column means where the cell sizes are used to
weight the cell means. |
| |
|
| Welch-Satterthwaite solution |
A solution to the problem of comparing means with
heterogeneous variances-- independently arrived at by Welch
and Satterthwaite. |
| |
|
| Whiskers |
Lines drawn in a boxplot from hinges to adjacent
values. |
| |
|
| Wilcoxon's matchedpairs signedranks
test |
A nonparametric test for comparing the central tendency
of two matched (related) samples. |
| |
|
| Wilcoxon's rank-sum test |
A nonparametric test for comparing two independent
groups. It is functionally equivalent to the Mann-Whitney U
test. |
| |
|
| Winsorized samples |
Samples in which extreme values have been trimmed and
replaced by the most extreme value(s) remaining in the
distribution. |
| |
|
| Yates' correction for continuity |
An old correction to adjust chi-square for a 2
X 2 table for the fact that cell
frequencies are integer, rather than continuous. Rarely
recommended any longer. |
| |
|
| z score |
Number of standard deviations above or below the
mean. |
| |
|

