

Part 1 of this document can be found at Mixed-Models-for-Repeated-Measures1.html .
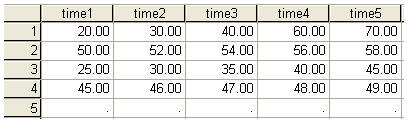
Because I was particularly interested in the analysis of variance, in Part 1 I approached the problem of mixed models first by looking at the use of the repeated statement in SAS Proc Mixed. Remember that our main problem in any repeated measures analysis is to handle the fact that when we have several observations from the same subject, our error terms are often going to be correlated. This is true whether the covariances fit the compound symmetry structure or we treat them as unstructured or autoregressive. But there is another way to get at this problem. Look at the completely fictitious data shown below.
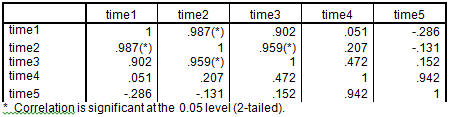
Now look at the pattern of correlations.
Except for the specific values, these look like the pattern we have seen before. I generated them by simply setting up data for each subject that had a different slope. For Subject 1 the scores had a very steep slope, whereas for Subject 4 the line was almost flat. In other words there was variance to the slopes. Had all of the slopes been equal (the lines parallel) the off-diagonal correlations would have been equal except for error, and the variance of the slopes would have been 0. But when the slopes were unequal their variance was greater than 0 and the times would be differentially correlated.
As I pointed out earlier, compound symmetry is associated directly with a model in which lines representing changes for subjects over time are parallel. That means that when we assume compound symmetry, as we do in a standard repeated measures design, we are assuming that pattern for subjects. Their intercepts may differ, but not their slopes. One way to look at the analysis of mixed models is to fiddle with the expected pattern of the correlations, as we did with the repeated command. Another way is to look at the variances in the slopes, which we will do with the random command. With the appropriate selection of options the results will be the same.
We will start first with the simplest approach. We will assume that subjects differ on average (i.e. that they have different intercepts), but that they have the same slopes. This is really equivalent to our basic repeated measures ANOVA where we have a term for Subjects, reflecting subject differences, but where our assumption of compound symmetry forces us to treat the data by assuming that however subjects differ overall, they all have the same slope. I am using the same missing data set that we used in the first part of the document for purposes of comparison.
Here we will replace the Repeated command with the Random command. The "int" on the random statement tells the model to fit a different intercept for each subject, but to assume that the slopes are constant across subjects. I am requesting a covariance structure with compound symmetry.
Options nodate nonumber nocenter formdlim = '-' linesize = 85;
libname lib 'H:\Supplements\Mixed Models Repeated';
Title 'Analysis of Wicksell missing data using random command';
/* Now read the data in the long format for Proc Mixed. */
/* Here I have entered time as 0, 1, 3, or 6. and I have extra variables to be ignored. */
Data lib.WicksellLongMiss;
infile 'C:\Users\Dave Desktop\Dropbox\Webs\StatPages\More_Stuff\Mixed-Models-Repeated\WicksellLongMiss.dat';
input subject group time dv centtime time1 newtime;
Label
Group = 'Treatment vs Control'
Time = 'Time of Measurement starting at 0'
;
timecont = time; /* This allows for time as a continuous var. */
run;
Title 'Analysis with random intercept.' ;
Proc Mixed data = lib.WickselllongMiss;
class group time subject ;
model dv = group time group*time/solution;
random int /subject = subject type = cs;
run;
Analysis with random intercept.
Covariance Parameter Estimates
Cov Parm Subject Estimate
Variance subject 2677.70
CS subject -119.13
Residual 2954.57
Fit Statistics
-2 Res Log Likelihood 905.4
AIC (smaller is better) 911.4
AICC (smaller is better) 911.7
BIC (smaller is better) 914.9
Null Model Likelihood Ratio Test
DF Chi-Square Pr > ChiSq
2 19.21 <.0001
Solution for Fixed Effects
Time of
Treatment Measurement
vs starting Standard
Effect Control at 0 Estimate Error DF t Value Pr > |t|
Intercept 111.87 23.7352 22 4.71 0.0001
group 1 89.6916 32.4127 57 2.77 0.0076
group 2 0 . . . .
time 1 168.54 24.4205 57 6.90 <.0001
time 2 -16.0695 25.1379 57 -0.64 0.5252
time 3 -11.0433 25.5271 57 -0.43 0.6669
time 4 0 . . . .
group*time 1 1 -65.7749 33.4153 57 -1.97 0.0539
group*time 1 2 68.64 34.3675 57 2.00 0.0506
group*time 1 3 25.8819 34.6532 57 0.75 0.4582
group*time 1 4 0 . . . .
group*time 2 1 0 . . . .
group*time 2 2 0 . . . .
group*time 2 3 0 . . . .
group*time 2 4 0 . . . .
-------------------------------------------------------------------------------------
Type 3 Tests of Fixed Effects
Num Den
Effect DF DF F Value Pr > F
group 1 57 16.52 0.0001
time 3 57 32.45 <.0001
group*time 3 57 6.09 0.0011
These results are essentially the same as those we found using the repeated command and setting type = cs. By only specifying "int" as random we have not allowed the slopes to differ, and thus we have forced compound symmetry. We would have virtually the same output even if we specified that the covariance structure be "unstructured."
Now I want to go a step further. Here I am venturing into territory that I know less well, but I think that I am correct in what follows.
Remember that when we specify compound symmetry we are specifying a pattern that results from subjects showing parallel trends over time. So when we replace our repeated statement with a random statement and specify that "int" is the only random component, we are doing essentially what the repeated statement did. We are not allowing for different slopes. But in the next analysis I am going to allow slopes to differ by entering "time" in the random statement along with "int." What I will obtain is a solution where the slope of time has a variance greater than 0. The commands for this analysis follow. Notice two differences. We suddenly have a variable called "timecont." Recall that the class command converts time to a factor. That is fine, but for the random variable I want time to be continuous. So I have just made a copy of the original "time," called it "timecont," and not put it in the class statement. Notice that I do not include "type = cs" in the following syntax because by allowing for different slopes I am allowing for a pattern of correlations that do not fit the assumption of compound symmetry. (The commands that follow assume that you have run earlier commands to establish the data file etc.)
Title 'Analysis with random intercept and random slope.' ;
Proc Mixed data = lib.WickselllongMiss;
class group time subject ;
model dv = group time group*time/solution;
random int timecont /subject = subject ;
run;
Covariance Parameter Estimates
Cov Parm Subject Estimate
Intercept subject 2557.79
timecont subject 0
Residual 2954.81
Fit Statistics
-2 Res Log Likelihood 905.4
AIC (smaller is better) 909.4
AICC (smaller is better) 909.6
BIC (smaller is better) 911.8
Solution for Fixed Effects
Time of
Treatment Measurement
vs starting Standard
Effect Control at 0 Estimate Error DF t Value Pr > |t|
Intercept 111.87 23.7344 22 4.71 0.0001
group 1 89.6920 32.4114 35 2.77 0.0090
group 2 0 . . . .
time 1 168.54 24.4214 35 6.90 <.0001
time 2 -16.0687 25.1388 35 -0.64 0.5269
time 3 -11.0428 25.5281 35 -0.43 0.6680
time 4 0 . . . .
group*time 1 1 -65.7753 33.4166 35 -1.97 0.0570
group*time 1 2 68.64 34.3688 35 2.00 0.0536
group*time 1 3 25.8808 34.6546 35 0.75 0.4602
group*time 1 4 0 . . . .
group*time 2 1 0 . . . .
group*time 2 2 0 . . . .
group*time 2 3 0 . . . .
group*time 2 4 0 . . . .
-------------------------------------------------------------------------------------
Analysis with random intercept and random slope.
Type 3 Tests of Fixed Effects
Num Den
Effect DF DF F Value Pr > F
group 1 35 16.53 0.0003
time 3 35 32.45 <.0001
group*time 3 35 6.09 0.0019
Notice that the pattern of results is similar to what we found in the earlier analyses (compared with both the analysis using the repeated command and the analysis without time as a random effect). However we only have 35 df for error for each test. The AIC for the earlier analysis in Part 1 of this document using AR(1) as the covariance structure had an AIC of 895.1, whereas here our AIC fit statistic is 909.4, which is higher. My preference would be to stay with the AR1 structure on the repeated command. That looks to me to be the best fitting model and one that makes logical sense.
There is one more approach recommended by Guerin and Stroop (2000). They suggest that when we are allowing a model that has an AR(1) or UN covariance structure, we combine the random and repeated commands in the same run. According to Littell et al., they showed that "a failure to model a separate between-subjects random effect can adversely affect inference on time and treatment × time effects."
This analysis would include both kinds of terms and is shown below.
proc mixed data = lib.WicklongMiss;
class group time subj ;
model dv = group time group*time/solution;
random subj(group);
repeated time/ type = AR(1) subject = subj(group) rcorr;
run;
Estimated R Correlation Matrix for subject 1
Row Col1 Col2 Col3 Col4
1 1.0000 0.6182 0.3822 0.2363
2 0.6182 1.0000 0.6182 0.3268
3 0.3822 0.6182 1.0000 0.6182
4 0.2363 0.3822 0.6182 1.0000
Covariance Parameter Estimates
Cov Parm Subject Estimate
subject(group) 0
AR(1) subject(group) 0.6182
Residual 5349.89
Fit Statistics
-2 Res Log Likelihood 895.1
AIC (smaller is better) 899.1
AICC (smaller is better) 899.2
BIC (smaller is better) 901.4
Null Model Likelihood Ratio Test
DF Chi-Square Pr > ChiSq
1 25.28 <.0001
Solution for Fixed Effects
Treatment
vs Time of Standard
Effect Control Measurement Estimate Error DF t Value Pr > |t|
Intercept 106.64 23.4064 22 4.56 0.0002
group 1 95.0006 31.9183 22 2.98 0.0070
group 2 0 . . . .
time 1 173.78 27.9825 57 6.21 <.0001
time 2 -8.9994 26.0818 57 -0.35 0.7313
time 3 -10.8539 21.6965 57 -0.50 0.6188
time 4 0 . . . .
group*time 1 1 -71.0839 38.5890 57 -1.84 0.0707
group*time 1 2 57.7765 35.6974 57 1.62 0.1111
group*time 1 3 26.6348 29.2660 57 0.91 0.3666
group*time 1 4 0 . . . .
group*time 2 1 0 . . . .
group*time 2 2 0 . . . .
group*time 2 3 0 . . . .
group*time 2 4 0 . . . .
Type 3 Tests of Fixed Effects
Num Den
Effect DF DF F Value Pr > F
group 1 22 17.32 0.0004
time 3 57 30.82 <.0001
group*time 3 57 7.72 <.0002
Because of the way that SAS or SPSS sets up dummy variables to represent treatment effects, the intercept will represent the cell for the last time and the last group. In other words cell24. Notice that that cell mean is 106.64, which is also the intercept. The effect for Group 1 is the difference between the mean of the last time in the first group (cell14 and the intercept, which equals 150.73 - 100.61 = 50.12(within rounding error). That is the treatment effect for group 1 given in the solutions section of the table. Because there is only 1 df for groups, we don't have a treatment effect for group 2, though we can calculate it as -50.12 because treatment effects sum to zero. For the effect of Time 1, we take the deviation of the cell for Time 1 for the last group (group 2) from the intercept, which equals 286.09 - 100.61 = 185.48. For Times 2 and 3 we would subtract 100.61 from 99.6843 and 94.6383, respectively, giving -0.9290 and -5.9750. With 3 df for Time, we don't have an effect for Time 4, but again we can obtain it by subtraction as 0 - (185.48+0.9290+5.9750) = -178.59. For the interaction effects we take cell means minus row and column effects plus the intercept. So for Time11 we have 301.20 - 50.1121-185.48+100.61) = -35.0057. Similarly for the other interaction effects.
I should probably pay a great deal more attention to these treatment effects, but I will not do so here. If they were expressed in terms of deviations from the grand mean, rather than with respect to cell24 I could get more excited about them. (If SAS set up its design matrix differently they would come out that way. But they don't here.) I know that most statisticians will come down on my head for making such a statement, and perhaps I am being sloppy, but I think that I get more information from looking at cell means and F statistics.
Well after this page was originally written and I thought that I had everything all figured out (well, I didn't really think that, but I hoped), I discovered that life is not as simple as we would like it to be. The classic book in the field is Littell et al. (2006). They have written about SAS in numerous books, and some of them worked on the development of Proc Mixed. However others who know far more statistics than I will ever learn, and who have used SAS for years, have had great difficulty in deciding on the appropriate ways of writing the syntax. An excellent paper in this regard is Overall, Ahn, Shivakumar, & Kalburgi (1999). They spent 27 pages trying to decide on the correct analysis and ended up arguing that perhaps there is a better way than using mixed models anyway. Now they did have somewhat of a special problem because they were running an analysis of covariance because missing data was dependent, in part, on baseline measures. However other forms of analyses will allow a variable to be both a dependent variable and a covariate. (If you try this with SPSS you will be allowed to enter Time1 as a covariate, but the solution is exactly the same as if you had not. I haven't yet tried this is R or S-Plus.) This points out that all of the answers are not out there. If John Overall can't figure it out, how are you and I supposed to?
That last paragraph might suggest that I should just eliminate this whole document, but that is much too extreme. Proc Mixed is not going to go away, and we have to get used to it. All that I suggest is a bit of caution. But if you do want to consider alternatives, look at the Overall et al. paper and read what they have to say about what they call Two-Stage models. Then look at other work that this group has done.
But I can't leave this without bringing in one more complication. Overall & Tonidandel (2007) recommend a somewhat different solution by using a continuous measure of time on the model statement. In other words, specifying time on the class variable turns time into a factor with 4 levels. I earlier said timecont = time in a data statement. Overall & Tonidandel would have me specify the model statement as model dv = group timecont group*timecont. / solution; Littell et al. 2006 refer to this as "Comparisons using regression," but it is not clear, other than to test nonlinearity, why we would do this. It is very close to, but not exactly the same as, a test of linear and quadratic components. (For quadratic you would need to include time2 and its interaction with group.) It yields a drastically different set of results, with 1 df for timecont and for timecont × group. The 1 df is understandable because you have one degree of freedom for each contrast. The timecont × group interaction is not close to significant, which may make sense if you look at the plotted data, but I'm not convinced. I am going to stick with my approach, at least for now.
The SAS printout follows based on the complete (not the missing) data.
Type 3 Tests of Fixed Effects
Effect Num DF Den DF F Value Pr > F
group 1 22 9.80 0.0049
timecont 1 70 29.97 <.0001
timecont*group 1 70 0.31 0.5803
Compare this with the Proc GLM solution for linear trend given earlier.
Contrast Variable: time_1 The Linear Effect of Time (intervals = 0,1,2,3)
Source DF Type III SS Mean Square F Value Pr > F
Mean 1 168155.6270 168155.6270 36.14 <.0001
group 1 1457.2401 1457.2401 0.31 0.5814
Error 22 102368.7996 4653.1273
They are not the same, though they are very close. (I don't know why they aren't the same, but I suspect that it has to do with the fact that Proc GLM uses a least squares solution while Proc Mixed uses REML.) Notice the different degrees of freedom for error, and remember that "mean" is equivalent to "timecont" and "group" is equivalent to the interaction.
There are many ways of dealing with missing values (Howell, 2008), but a very common approach is known as Estimation/Maximization (EM). To describe what EM does in a very few sentences, it basically uses the means and standard deviations of the existing observations to make estimates of the missing values. Having those estimates changes the mean and standard deviation of the data, and those new means and standard deviations are used as parameter estimates to make new predictions for the (originally) missing values. Those, in turn, change the means and variances and a new set of estimated values is created. This process goes on iteratively until it stabilizes.
I used a (freely available) program called NORM (Shafer & Olson, 1998) to impute new data for missing values. (For a discussion of NORM, see MissingDataNorm.html. I then took the new data, which was now a complete data set, and used Proc GLM in SAS to run the analysis of variance on the completed data set. I repeated this several times to get an estimate of the variability in the results. The resulting Fs for three replications are shown below, along with the results of using Proc Mixed on the missing data with an autoregressive covariance structure and simply using the standard ANOVA with all subjects having any missing data deleted.
Missing Cases
Replication 1 Replication 2 Replication 3 AR1 Deleted
Group 17.011 15.674 18.709 18.03 8.97
Time 35.459 33.471 37.960 29.55 27.34
Group * Time 5.901 5.326 7.292 7.90 2.81
I will freely admit that I don't know exactly how to evaluate these results, but they are at least in line with each other except for the last column when it uses casewise deletion. I find them encouraging.
dch