Online Appendices for
The emotional arcs of stories are dominated by six basic shapes. [blog post] [arXiv] [EPJ]
by Andrew J. Reagan, Lewis Mitchell, Dilan Kiley, Christopher M. Danforth, and Peter Sheridan Dodds
Abstract
Advances in computing power, natural language processing, and digitization of text now make it possible to study our a culture's evolution through its texts using a "big data" lens. Our ability to communicate relies in part upon a shared emotional experience, with stories often following distinct emotional trajectories, forming patterns that are meaningful to us. Here, by classifying the emotional arcs for a filtered subset of 1,737 stories from Project Gutenberg's fiction collection, we find a set of six core trajectories which form the building blocks of complex narratives. We strengthen our findings by separately applying optimization, linear decomposition, supervised learning, and unsupervised learning. For each of these six core emotional arcs, we examine the closest characteristic stories in publication today and find that particular emotional arcs enjoy greater success, as measured by downloads.
Interactive visualizations
We provide detailed, interactive visualizations (as pictured below) of all Project Gutenberg books at http://hedonometer.org/books/v3/1/ and a selection of classic and popular books at http://hedonometer.org/books/v1/.
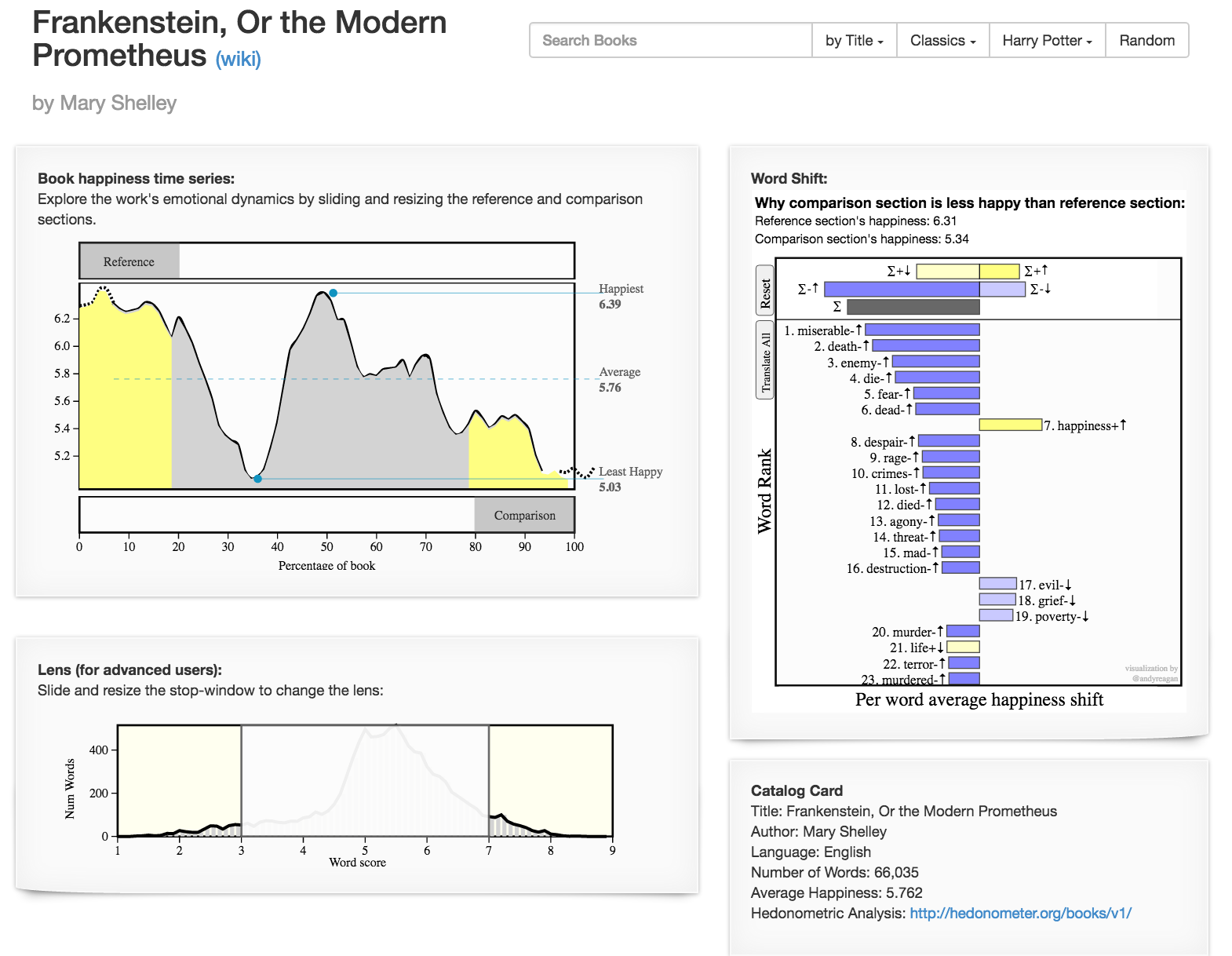
Additional Data
Book lists for each mode
Above is a list of each mode, labeled by the SV mode number (so, the first two modes are mode01-pos and mode01-neg). We have also sorted them by downloads (mode01-pos-dowloads), and by how close they are to the mode (mode01-pos-closest), such that their are two versions of the file for each mode. The ones that are "closest" have the greatest relative magnitude of their coefficient from the particular mode (we have sorted by their mode coefficient). Inside of each file is the gutenberg ID, # dowloads, and the book title (in that order, on each line).
Books used in this study
The IDs of the 1,737 Project Gutenberg books used in this study can be downloaded above.
Emotional arcs for each book
Time series for each of the books can be downloaded from the above folder, with each file name corresponding to the book ID. The above link will list a large directory (scrape however desired). In the ID.csv file is a 10,222x200 matrix with the count of each labMT word in each colum, for each of the 200 points in the time series (e.g. the first row will be the count of the word "laughter" through the book). The .txt file is the raw text used in the study.
Source code used for analysis
A collection of Jupyter notebooks, python scripts, and shell scripts used to perform the analysis for the paper.