Is language evolution grinding to a halt? The scaling of lexical turbulence in English fiction suggests it is not
E. A. Pechenick, C. M. Danforth, and P. S. Dodds
Times cited: 3
Logline: A rich exploration of the Google Books 2012 English Fiction corpus shows that while word birth is slowing down, word death is not increasing and the overall Zipf distribution has changed little from 1820 to 2000. However, superlinear scaling of `lexical turbulence' with word rank shows that the English language has been consistently and dramatically turning over internally throughout the same time span. The analysis gives insight into linguistic and cultural evolution, and indicates that future iterations of Google Books, the Fiction corpus should have critical, scholarly works separated out.
Abstract:
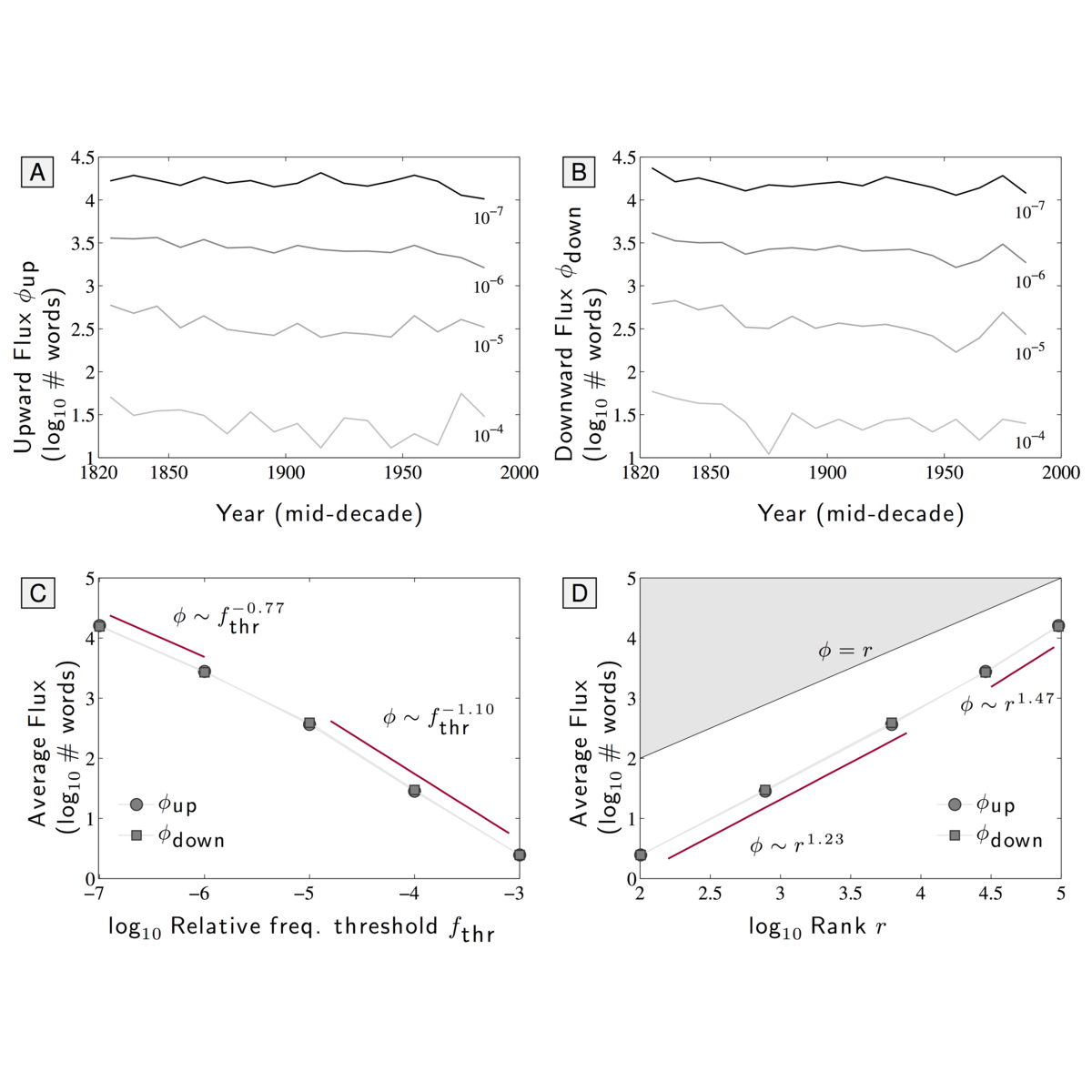
Of basic interest is the quantification of the long term growth of a language's lexicon as it develops to more completely cover both a culture's communication requirements and knowledge space. Here, we explore the usage dynamics of words in the English language as reflected by the Google Books 2012 English Fiction corpus. We critique an earlier method that found decreasing birth and increasing death rates of words over the second half of the 20th Century, showing death rates to be strongly affected by the imposed time cutoff of the arbitrary present and not increasing dramatically. We provide a robust, principled approach to examining lexical evolution by tracking the volume of word flux across various relative frequency thresholds. We show that while the overall statistical structure of the English language remains stable over time in terms of its raw Zipf distribution, we find evidence of an enduring `lexical turbulence': The flux of words across frequency thresholds from decade to decade scales superlinearly with word rank and exhibits a scaling break we connect to that of Zipf's law. To better understand the changing lexicon, we examine the contributions to the Jensen-Shannon divergence of individual words crossing frequency thresholds. We also find indications that scholarly works about fiction are strongly represented in the 2012 English Fiction corpus, and suggest that a future revision of the corpus should attempt to separate critical works from fiction itself.
- This is the default HTML.
- You can replace it with your own.
- Include your own code without the HTML, Head, or Body tags.
BibTeX:
@Article{pechenick2015b,
author = {Pechenick, Eitan A. and Danforth, Chrisopher M. and Dodds, Peter Sheridan},
title = {Is language evolution grinding to a halt? {T}he scaling of lexical turbulence in {E}nglish fiction suggests it is not},
year = {2015},
key = {language,culture,evolution},
note = {Available online at \href{http://arxiv.org/abs/1503.03512}{http://arxiv.org/abs/1503.03512}},
}